引言¶
消息队列(MQ, Message Queue),是一种异步通信机制,允许应用程序发送消息到队列,而不必等待接收方处理这些消息,通过中间件在发送方和接收方之间提供消息缓冲和路由功能。
消息队列是架构中最常见的中间件之一,适用于很多场景,比如
- 上游流量忽高忽低,用来削峰填谷,提升 CPU/GPU 利用率。
- 系统过大,消息流向盘根错节,用来拆解组件,降低系统耦合。
- 秒杀活动,请求激增,用来保护服务的同时又尽量不影响用户。
常见的与消息队列相关的协议或标准有
JMSJava MessageService,实际上是个 Java APIAMQPAdvanced Message Queuing Protocol,最初用于解决金融领域跨平台消息传递问题,生产者与消费者可以使用不同语言开发- 其它:
MQTT、STOMP、OpenMessaging
目前为止还没有谁能统一标准,基于以上标准和协议开发的消息队列有
- ActiveMQ 最老牌,是十年前唯一可供选择的开源消息队列,目前已快被淘汰,它存在的意义仅限于兼容那些还在用的老旧系统。
- RabbitMQ 使用最广泛的轻量级 MQ,开箱即用,支持多种协议,包括 AMQP、MQTT、STOMP 等,有更广泛的语言和框架支持,性能相比其它 MQ 要差很多。
- Kafka 目前是生态兼容最好的 MQ,尤其在大数据和流计算领域,缺点是同步收发消息的响应时延比较高,不太适合在线业务场景。
- RocketMQ 兼容性较差,只在国内比较流行,主要场景是处理在线业务。
- Pulsar 新兴的开源 MQ,最初由 Yahoo 开发,现在也属于 Apache 软件基金会,采用存储和计算分离的设计,目前还处于成长期。
- ZeroMQ 严格来说只是一个基于消息队列的多线程网络库,如果你的需求是将消息队列的功能集成到你的系统进程中,可以考虑使用。
- Redis 也支持 MQ 功能
Kafka¶
由 Linkedin 使用 Scala 和 Java 开发,后开源给 Apache 软件基金会。
如果有两个服务,A 服务可发出 200 QPS,而 B 服务只能处理 100 QPS,则 B 服务会被压垮,所以需要在 B 服务前增加一个队列。
队列可以用链表实现,链表的每个节点就是一个消息,对应一个序号 offset,记录消息的位置。
但队列不能与 B 服务处于同一进程,因为 B 服务崩溃重启后,未处理的数据会丢失,所以需要一个单独的进程,部署在 A 和 B 之间,即 MQ。
参考:https://mp.weixin.qq.com/s/SNMmCMV-gqkHtWS0Ca3j4g
高性能¶
为了提高性能,可以增加更多的消费者处理数据,相对的也可以增加生产者,提升吞吐量
- topic
随着生产者和消费者变多,为避免出现同时争抢同一个消息队列而等待的情况,需要对消息进行分类每一类是一个 topic,生产者按照 topic 将数据分发到不同的队列中,消费者根据需要订阅不同的 topic。
- partition
还可以将单个的 topic 分成多段,每一段是一个 partition 分区,订阅同一 topic 的消费者可以对接不同的分区,进一步避免争抢。
高扩展¶
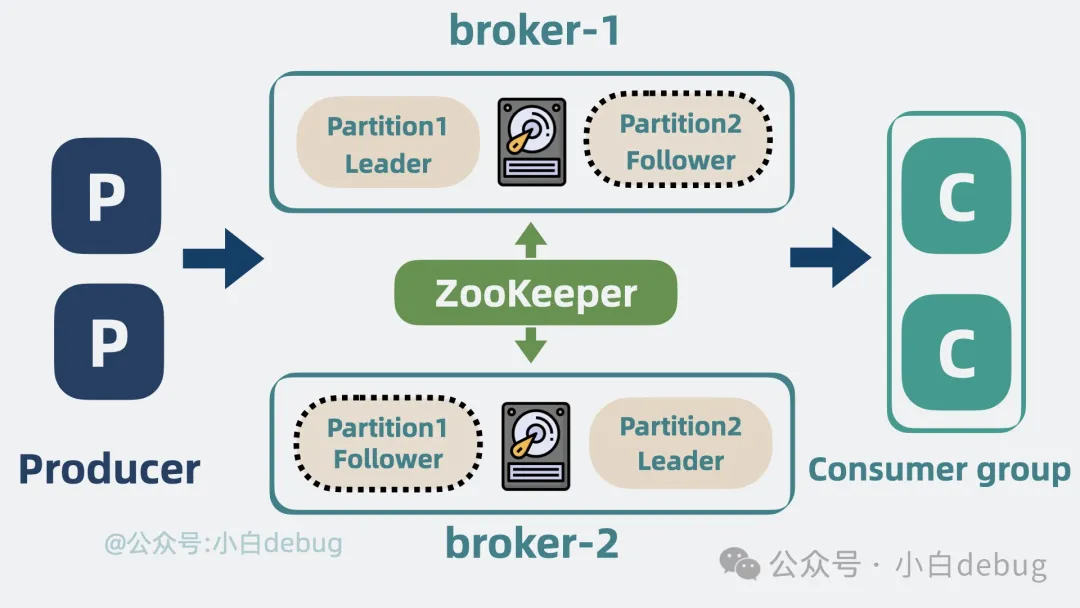
- broker
随着 partition 变多,会导致单机 CPU 和内存过高,影响整体系统性能。可以将 partition 分散部署在多台机器上,每台机器代表一个 broker。
- 分布式协调服务
组件过多,每个组件都有自己的数据和状态,需要引入分布式协调服务定期和 broker 通信,获取 整个 kafka 集群的状态,比如 ZooKeeper。
但 ZooKeeper 过重,Kafka 其实只用到了它的部分功能,所以从 2.8.0 版本开始支持移除 ZooKeeper,通过一致性算法 Raft 实现同样的效果,即所谓的 Kraft 或 Quorum 模式。
高可用¶
- replicas
如果某个 broker 挂了,则对应的 partition 数据就没了,可以给 partition 增加副本 replicas 来解决,形成 Leader 和 Follower 的关系,Leader 负责应付生产者和消费者的读写请求,而 Follower 只管同步 Leader 的消息。将 Leader 和 Follower 分散到不同的 broker 上,这样 Leader 所在的 broker 挂了,也不会影响到 Follower 所在的 broker, 并且还能从 Follower 中选举出一个新的 Leader。
持久化¶
为避免极端情况下所有 broker 都挂掉导致内存中的数据全部丢失,需要将数据存储到磁盘。
磁盘的容量也是有限的,所以还要加上保留策略 retention policy,在数据过大或者过期时清理数据。
RocketMQ¶
由阿里 12 年使用 Java 开发,17 年捐赠给 Apache 软件基金会
RocketMQ 参考了 Kafka,看起来更强,但性能却不如 Kafka
参考:https://mp.weixin.qq.com/s/oje7PLWHz_7bKWn8M72LUw
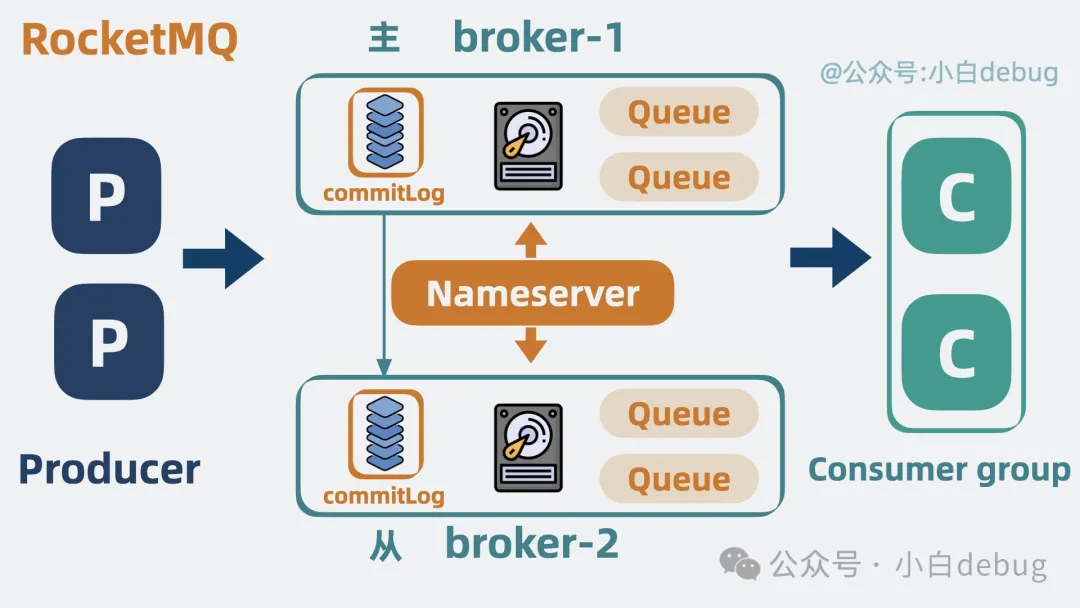
在架构上做了一些减法¶
比如把 ZooKeeper 换成了更轻量的 Nameserver 管理消息队列集群
为了缓解同时写多个文件带来的随机写问题导致的性能降低,把分区 partition 换成了队列 Queue + commitLog,所有写操作都变为了顺序写,提升了在多 topic 场景下的写性能。
并因此简化了备份模型,即直接备份 Broker 而不是 commitLog。
在功能上做了一些加法¶
- 消息标记
在 topic 分类的基础上还可以进一步分类,支持对消息打标记 Tag,比如 VIP 等级,消费者可以根据 Tag 过滤所需要的数据,减少资源消耗
- 支持事务
执行一些自定义逻辑和生产者发消息这两件事组成一个事务,要么同时成功,要么同时失败。
- 延时队列
消息发送到 MQ 后,禁止消费者立刻消费,Kafka 中需要程序员自己实现
- 死信队列
消费者消费消息是有可能失败的,如果多次重试失败,则会把消息放到一个专门的死信队列中,方便后续单独处理,Kafka 中需要程序员自己实现
- 消息回溯
Kafka 支持通过调整 offset 让消费者从某个地方开始消费,而 RocketMQ 除了可以调整 offset,还支持调整时间,不过 Kafka 0.10.1 版本后也支持了