Redis¶
假设某个服务对外提供 10k/s 次查询,但背后的 MySQL 只支持 5k QPS,完全扛不住,这类大流量查询的场景很常见,比如秒杀活动或者抢票,怎么办,没有什么是加个中间层不能解决的,MySQL 主要存储在磁盘中,我们知道查询内存比查询磁盘的速度要快,所以如果能把数据放在内存中,则可以大幅提升查询性能。
- 本地缓存
比如可以在内存中申请一个字典,作为本地缓存,查询的时候优先去字典中找数据,通过 key 查询对应的 value,找不到再去查 MySQL,然后返回给用户的同时缓存到字典中,下次就可以直接在字典中查询到。
- 远程缓存
为了保障系统高可用,一般服务通常都不止一个实例,如果每个实例都各自使用一份本地缓存则会造成内存浪费,所以考虑将字典抽离出来,单独做成一个远程缓存服务
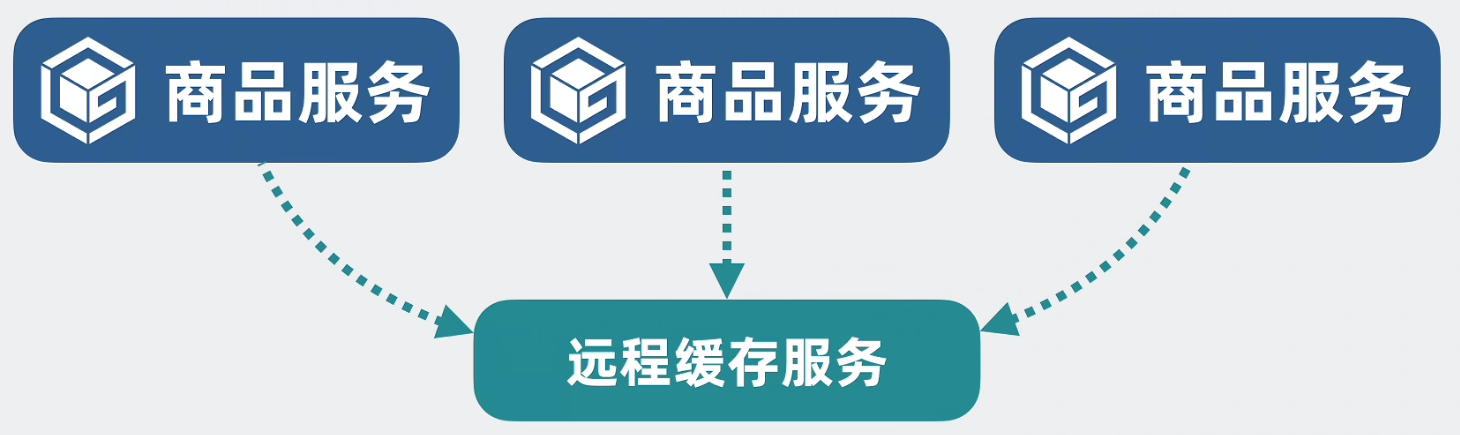
但被多个服务调用时会出现并发问题,解决方式是,不管有多少个网络连接,都统一塞到一个线程上,使用单线程对字典进行读写,即可避免并发问题和线程切换开销。
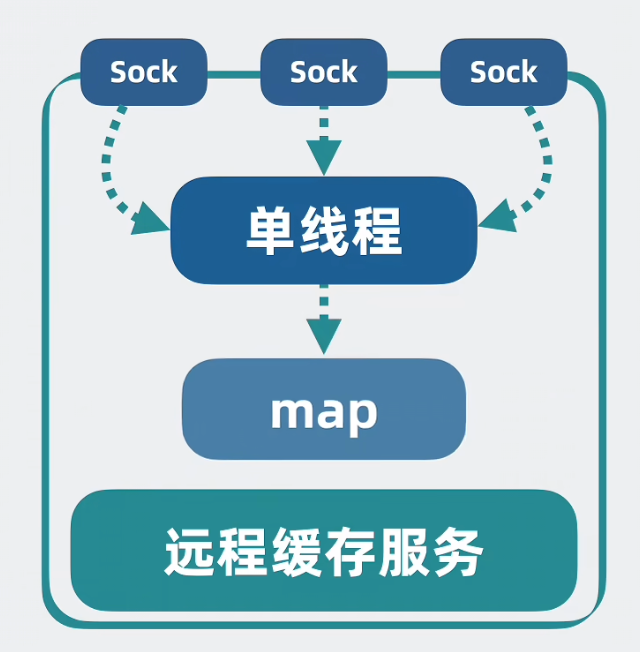
针对以上服务进行优化
- 支持多种数据类型
字典的 key 是字符串,但 value 支持多种类型,除了字符串外,还可以支持先进先出(FIFO)的 List,可以去重的 Set,可以做排行榜的 ZSet
- 缓存过期
随着缓存的数据越来越多,需要一些过期策略让宝贵的内存空间不被浪费,何时过期,客户端可以设置
- 缓存淘汰策略
虽然客户端可以设置过期时间,但不可控,所以还需要缓存服务自己增加一些淘汰策略,比如可以将最近最少使用的内存删掉,即所谓的 LRU(Least Recently Used)
- 持久化
一旦缓存服务重启,那内存里的缓存数据就都没了,所以考虑在缓存服务里加一个异步子进城,定期将全量内存数据生成快照持久化到磁盘文件里,来保证重启后通过加载快照文件恢复缓存数据,这就是所谓的 RDB,还有一种 AOF 方式。
- 简化传输协议
通过 TCP 协议直接传输
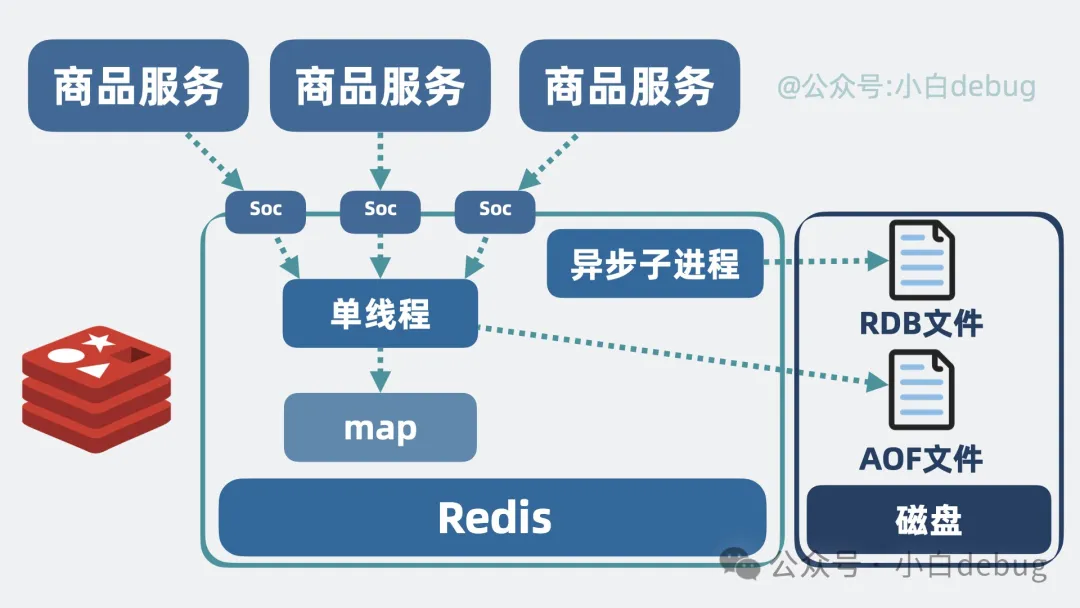
经过优化后的远程缓存服务,变成一个高性能、支持多种数据类型、和各种缓存淘汰策略、并提供一定的持久化能力的超级缓存服务,这就是我们常说的 Redis(Remote Dictionary Server)
Redis 使用 ANSI C 语言编写,采用单进程单线程模型和非阻塞多路 I/O 复用机制,查询效率非常高,根据官方提供的数据,每秒最多处理的请求可以达到 10 万次。
MySQL 作为数据库,提供持久化功能,并通过主从架构提高数据库服务的高可用性,实际场景中大多数情况下可能都是读操作,可以用 Redis 作为 MySQL 的缓存,降低 I/O 的访问,解决读写效率要求很高的请求,不过它存储的数据量有限,适合存储热点数据。
Redis 作为缓存服务只是最基础的用法,通过扩展插件可以实现更高级的玩法,可以将各种中间件在内存里实现一遍,比如 RedisJson 支持复杂的 JSON 查询和更新,相当于内存版的 MongoDB RedisSearch 就是一个简单的内存版的 ES,RedisGraph 支持图数据库功能,类似 neo4j,RedisTimeSeries 处理时间序列数据,即内存版的 InfluxDB
如果要支持高可用高扩展就涉及到主从、哨兵、集群模式等。
redis-server¶
- 源码安装
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
cd redis-stable
make
make install # 安装到:/usr/local/bin
- Ubuntu
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update
sudo apt-get install redis
- Windows 官方不支持
- Mac
brew install redis # 安装
# 前台启动服务,Ctrl-C停止服务
redis-server
# 后台启动服务
brew services start/stop redis
- Docker
# 启动服务
docker run --name some-redis -d redis
'
docker run --name some-redis -d redis redis-server --save 60 1 --loglevel warning
持久化存储,可自定义路径:-v /docker/host/dir:/data
'
# 连接
docker run -it --network some-network --rm redis redis-cli -h some-redis
redis-cli¶
连接服务
redis-cli
'
-h 127.0.0.1
-p 6379
-a "password" 测试环境可省略
--raw 避免中文乱码
'
连接后,命令行提示符显示为:127.0.0.1:6379>
ping # 检测服务是否启动,成功返回PONG
info # 查看服务端信息
quit # 退出连接
CONFIG GET dir # 获取安装目录,"/usr/local/redis/bin"
save # 备份当前数据库到安装目录中的dump.rdb文件
'
默认支持16个库(可以通过配置文件支持更多,无上限),从0开始递增数字命名
连接后会自动选择0号数据库,可手动切换
'
select 1
GUI 客户端¶
- RESP
以前叫做 Redis Desktop Manager,目前已收费,可试用14天,官网个人版 ¥129/年,苹果/微软应用商店¥98/永久(不能跨平台使用)
可能是目前最好的开源客户端
Mac 上启动如果报错可以执行:sudo xattr -rd com.apple.quarantine /Applications/Another\ Redis\ Desktop\ Manager.app
数据模型和操作¶
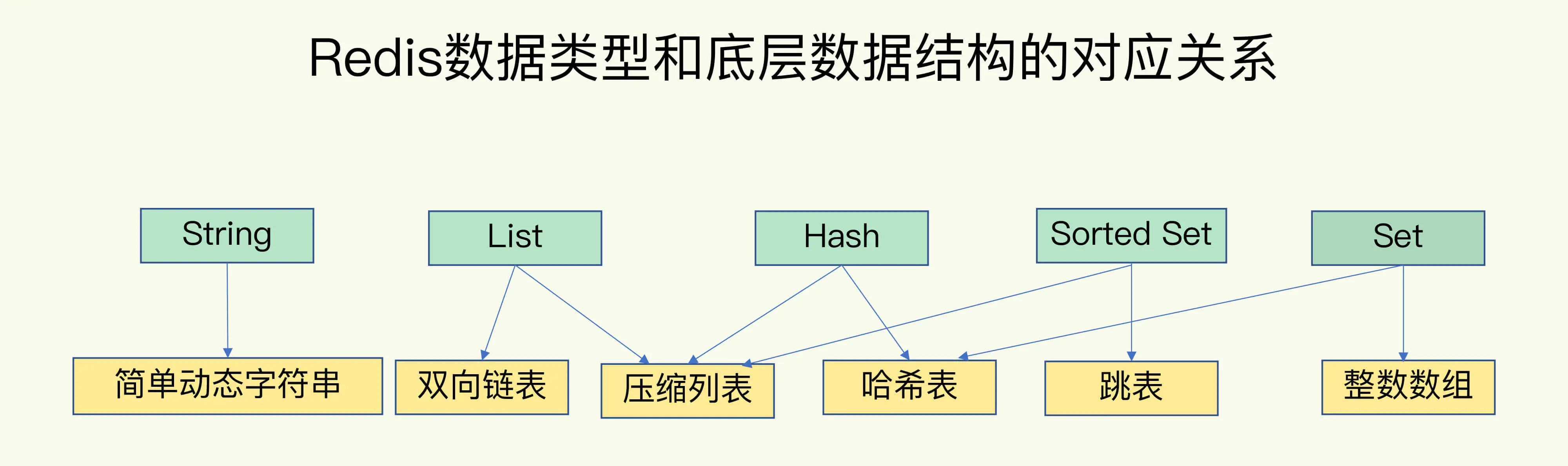
对于键值数据库而言,基本的数据模型是 key-value 模型,在对键值数据库进行选型时,一个重要的考虑因素是它支持的 value 类型,也就是数据的保存形式
- Memcached 仅支持 String 类型
- Redis 能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的 value。
不同键值数据库采用的索引并不相同,不同的索引结构在性能、空间消耗、并发控制等方面具有不同的特征
- RocksDB 采用跳表
- Memcached 和 Redis 则采用哈希表作为 key-value 索引。
type key # 查看key的类型
del key # 删除key
String¶
字符串
# set key value
set name zhangsan # 创建、更新
# 获取
get name
Hash¶
哈希,类似其他语言的字典或对象
# 添加:hset key field value
hset dict1 username zhangsan
hset dict1 age 28
# 设置多个 field:hmset key field1 value1 field2 value2...
hmset dict1 username zhangsan age 28
# 删除字段
hdel dict1 age
# 获取 field
hkeys dict
'
1) "username"
2) "age"
'
# 获取 value
hget user1 age # "28"
# 获取多个 field 的 value
hmget user1 username age
'
1) "zhangsan"
2) "28"
'
List¶
有序的字符串列表,按插入顺序排序
# LPUSH/RPUSH key value [...]
lpush list zhangfei guanyu liubei # 向列表左侧添加元素
rpush list dianwei lvbu # 向列表右侧添加元素
# 删除
lrem list num value
'
num=0 删除所有value元素
num>0 从左边查找,删除第n个
num<0 从右边查找,删除第n个
'
# 返回列表长度
llen list
# 获取指定 index 的元素
lindex list 1
# LRANGE key start stop
lrange list 0 -1 # 获取所有元素
'
1) "liubei"
2) "guanyu"
3) "zhangfei"
'
Set¶
无序的字符串集合,元素不能重复
# SADD key member [...]
sadd sets zhangfei guanyu liubei dianwei lvbu
# 删除
srem sets liubei lvbu
spop sets # 随机删除并返回被删除元素
# 获取
scard set # 获取集合长度
smembers sets # 获取集合元素
ZSet¶
有序的字符串集合,元素不能重复,SortedSet,简称 ZSet,按 score 排序(添加元素时指定 score)
ZSet 与 List 都是有序的,区别在于底层实现不同,List 操作两端的元素很快,但操作中间元素较慢,而 ZSet 操作中间元素也很快,而且通过 score 调整顺序也比 List 更高效,只需要改变 score 大小即可
# ZADD key score member [...]
zadd heroScore 8341 zhangfei 7107 guanyu 6900 liubei 7516 dianwei 7344 lvbu
# 删除
zrem heroScore guanyu
# 获取
zcard heroScore # 获取集合长度
zscore heroScore liubei # 获取score
# 排序
ZREVRANGE heroScore 0 2 # 显示排名前三的英雄及数值
'
ZREVRANGE key start stop [WITHSCORES] # 按score从大到小排
ZRANGE key start stop [WITHSCORES] # 按score从小到大排
可选项withscore 显示score分数
'
Streams¶
数据流,5.0 版本新增的,主要用于消息队列
RedisJSON¶
存储 JSON 数据,如果更新不频繁,可以用 String,比如说把用户的登陆信息转成 JSON 字符串后缓存起来,频繁则用 Hash
如果需要复杂操作,则需要 Redis 5.0+,安装 RedisJSON 模块,直接支持存储 JSON 类型
过期数据处理¶
随着缓存的数据越来越多,需要给缓存加一个过期时间(由应用程序设置),定期清理过期数据
但如果全部扫描一遍要花费大量时间,所以选择随机删除
但有可能某些数据一直不会被随机算法选中,所以又增加了惰性删除,即如果有请求访问到过期数据,则立刻删除
但如果有些键值一直没有请求,则依然不会被删除而占据内存空间,所以还需要内存淘汰策略。
- 缓存穿透:查询的数据如果不存在,则无法缓存
- 缓存击穿:如果某热点数据缓存过期被删除时恰好遇到大规模请求,则请求会抵达 MySQL
- 缓存雪崩:如果恰巧一大批热点数据缓存同时过期
所以应用程序最好将缓存过期时间设置的分散一些,还可以将热点数据设置为永不过期。
持久化存储¶
Memcached 和 Redis 都是属于内存键值数据库,但 Redis 有两种持久化存储方式
键值对保存在内存和外存的优缺点
保存在内存的好处是读写很快,毕竟内存的访问速度一般都在百 ns 级别,但是,潜在的风险是一旦掉电,所有的数据都会丢失。
保存在外存,虽然可以避免数据丢失,但是受限于磁盘的慢速读写(通常在几 ms 级别),键值数据库的整体性能会被拉低。
- RDB(快照,默认):是将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次的文件,达到数据恢复。
- AOF(日志):是将执行过的指令记录下来,数据恢复时按照从前到后的顺序再将指令执行一遍实现数据恢复。
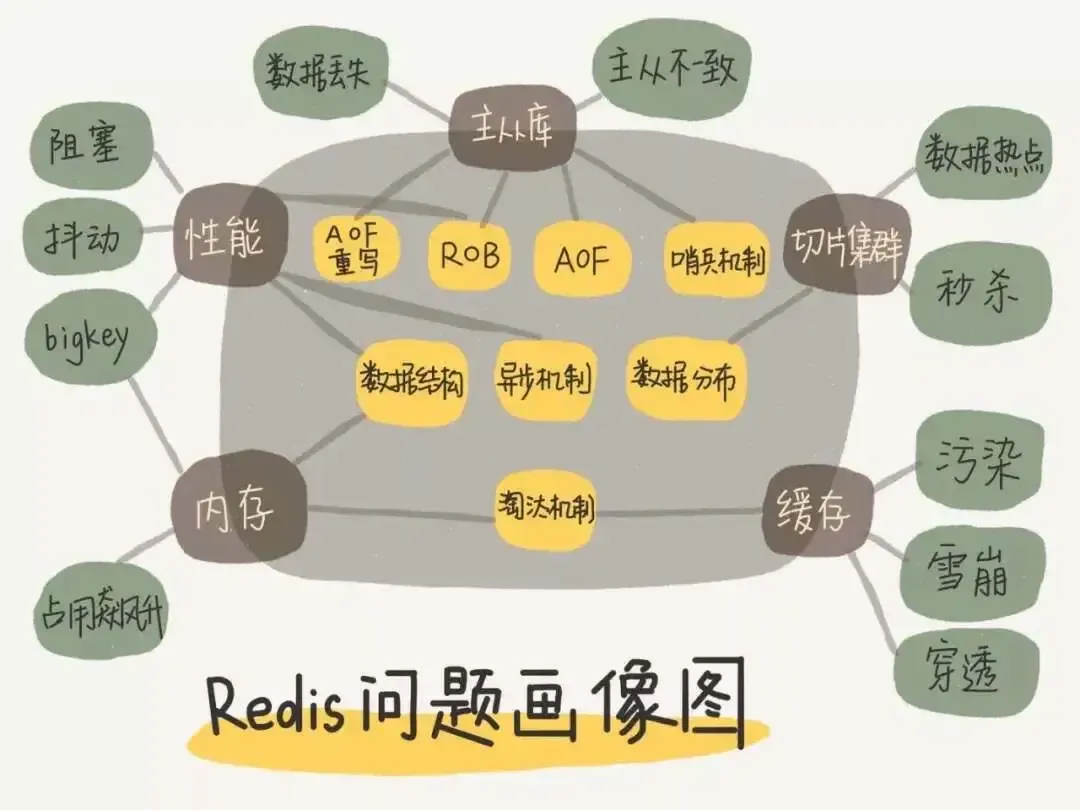
问题画像图¶