索引¶
把表中某列的值存储到某种数据结构中,就叫索引
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样,索引就是数据表的目录
适合建立索引的字段:主键,外键,频繁作为查找或排序的字段
分类
- 主键索引(聚簇索引)
- 普通索引(二级索引)
- 唯一索引,可以为 NULL
优点
- 提高数据检索效率,降低数据库 IO 成本
- 通过索引对数据进行排序,降低 CPU 消耗
缺点
- 占用空间
- 降低了表更新的速度
- 建立最优索引需要花时间研究
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高,像性别这种列有索引反而会降低效率,这种情况下大数据中会使用分组的概念
索引模型¶
在 MySQL 中,索引是在存储引擎层实现的,而 MySQL 的存储引擎是插件化的,所以并没有统一的索引标准,不同存储引擎的索引的工作方式并不一样。
即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。
常见的可用于存储索引的数据结构有:哈希表、有序数组和搜索树
数据库底层存储的核心就是基于这些数据模型的,每碰到一个新数据库,我们需要先关注它的数据模型,这样才能从理论上分析出这个数据库的适用场景
哈希表¶
以 Key-Value 形式查找数据,而 Value 会存储在数组中,对应的 index 是 Key 经过哈希函数换算而成的
但不同的 Key 可能会换算出同一个 index,这种情况需要引入链表,比如下图 User2 和 User4 都存储在 index_N 这个位置,当要查询 ID_card_n2 的时候先通过哈希函数算出 index 为 N,然后再遍历对应的链表,即可找到对应的 Value name2。
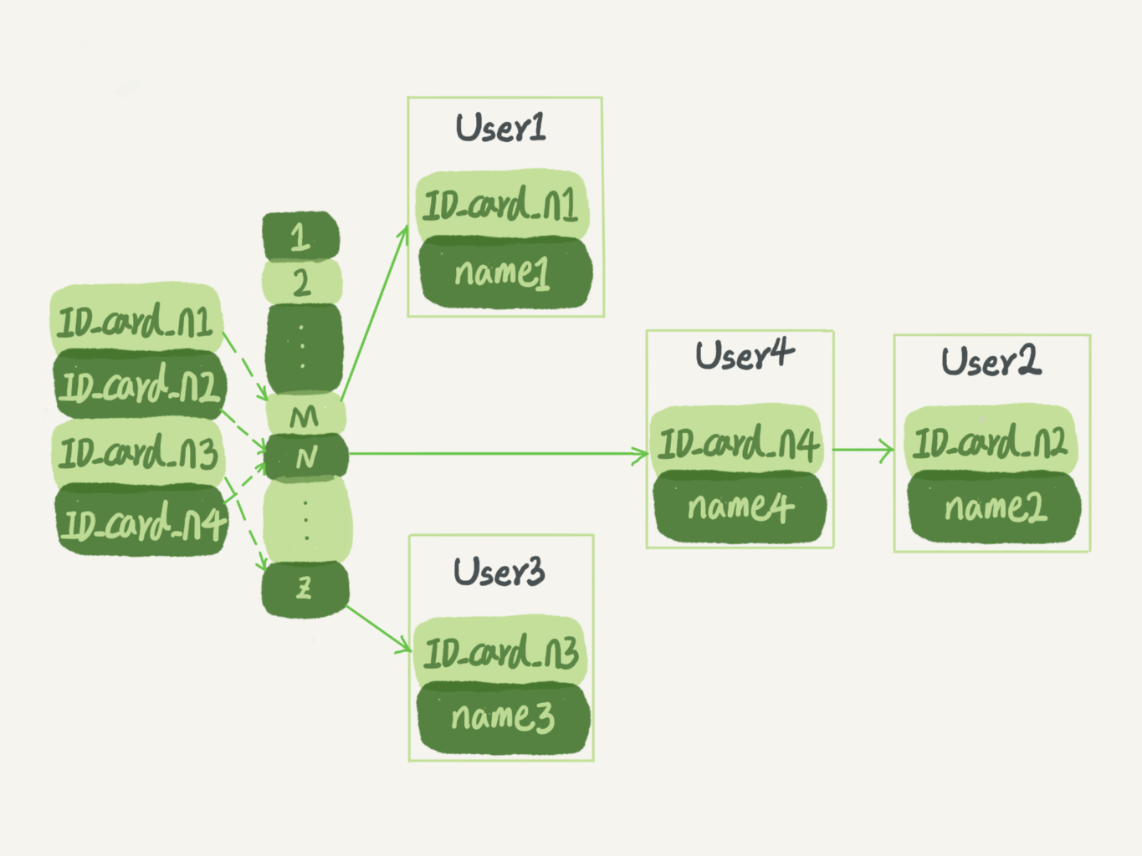
哈希表存储不是有序递增的,所以做区间查询是很慢的,适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
有序列数组¶
有序数组在等值查询和范围查询场景中的性能就都很高效,但更新数据成本就比较高了,只适用于静态存储引擎,比如保存不会再变的存档数据

搜索树¶

树操作的复杂度与树的高度成正比,节点数相同的情况下,增加树的分叉即可降低树的高度
另外树的根节点总是存储在内存中,第二层节点大概率存储在内存中,但其他层节点一般存储在磁盘中
所以二叉搜索树的效率虽然最高,但为了尽可能少的读取磁盘,实际数据库存储中使用的都是 N 路搜索树
N 取决于数据块的大小,比如 InnoDB 存储整数字段的索引时,N≈1200 叉,树高为 4 的话,可以有 1200^3 个节点,约 17 亿
InnoDB 使用了 B+ 树索引模型,每个索引对应一棵 B+ 树
在 InnoDB 中,每个表都会有一个主键索引,如果用户没有自定义主键,InnoDB 会为表自动创建一个名为 gen_clust_index 的隐藏的 6 字节的自增列
所以表是根据主键顺序以索引的形式存放的,即主键索引(也叫聚簇索引)的叶子节点存的是整行数据,而普通索引(也叫二级索引)的叶子节点内容是主键的值
也就是说主键查询只需要搜索 ID 这颗树,而普通索引需要先搜索 k 这颗树,得到 ID 的值,然后再搜索主键索引树(这个过程叫做回表)。
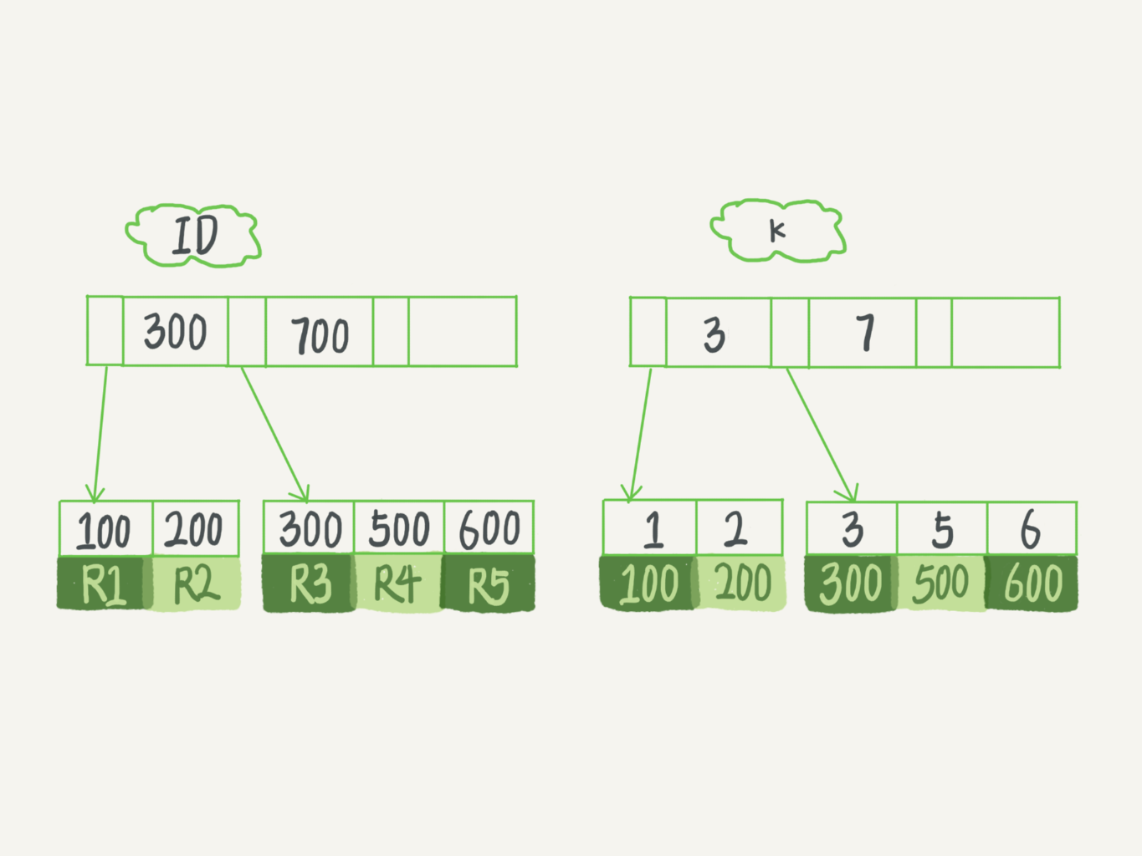
在满足语句需求的情况下, 尽量少地访问资源是数据库设计的重要原则之一。我们在使用数据库的时候,尤其是在设计表结构时,也要以减少资源消耗作为目标
尽可能减少回表操作
- 优先使用主键查询
- 使用覆盖索引查询
-- 先搜索k树,再搜索ID树
select * from T where k between 3 and 5
-- 覆盖索引,只搜索k树,因为要查找的目标是ID,搜索k树就可以覆盖目标了
select ID from T where k between 3 and 5
- 减少索引个数
如果两个字段经常被一起查询,则可以考虑设置联合索引,但要注意顺序,InnoDB 遵循最左前缀原则,把最常查询的放到左边,这样使用一个联合索引则可以替代两个单独的索引
- 索引下推
MySQL 5.6 引入的索引下推优化(index condition pushdown),可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数
性能优化¶
I/O 是 DBMS 最容易出现瓶颈的地方,可以说数据库操作中有大量的时间都花在了 I/O 上。
慢 SQL 优化,指的是对那些在执行过程中花费较长时间的 SQL 查询进行优化,以提高其执行速度和整体性能
慢 SQL 查询的常见原因
- 缺少索引:查询涉及的表没有适当的索引,导致全表扫描。
- 不合适的索引使用:索引使用不当或者复合索引未能被正确利用。
- 不合理的查询设计:查询语句本身设计不当,如使用了大量的嵌套子查询、未优化的 JOIN 等。
- 数据量过大:查询涉及的数据量过大,没有进行分页或分区。
- 服务器资源不足:数据库服务器的 CPU、内存或磁盘 I/O 资源不足。
- 锁竞争:并发查询之间发生锁竞争,导致查询等待时间增加。
比如对索引字段做函数操作,或有隐式类型转换涉及函数操作,或有隐式字符编码转换,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能,导致全索引扫描。
因此用 explain + SQL 语句 分析一下,是一个很好的习惯,它可以模拟优化器执行 SQL 查询语句。
- 尽量只查询所需要的列
- 当你知道只有 1 条记录的时候,就可以使用
LIMIT 1来进行约束