数据控制¶
数据库服务器 -> 数据库 -> 数据表 -> 行与列
-- 查看用户
select user,host from mysql.user;
/*
+------------------+-----------+
| user | host |
+------------------+-----------+
| demo | % |
| root | % |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
+------------------+-----------+
5 rows in set (0.00 sec)
*/
-- 创建用户(%表示所有IP都可以访问)
CREATE USER 'qadmin'@'%' IDENTIFIED BY 'passwd';
-- 删除用户
drop user 'test1'@'localhost';
-- 修改用户密码(旧版本修改密码的方式在8.0版本不再适用)
alter user 'root'@'localhost' identified with mysql_native_password by '111111'
-- 查看用户授权信息
show grants for 'qadmin'@'%';
-- 授予所有权限
grant all privileges on *.* to 'qadmin'@'%' with grant option;
-- 刷新系统权限相关的表
flush privileges;
-- 撤销权限
revoke all privileges on *.* from 'qadmin'@'%';
字符集¶
-- 显示字符集相关变量
show variables like '%char%';
/*
存储字符集
utf8 支持最长三个字节的UTF-8字符
utf8mb4 支持四字节的UTF-8字符,默认,推荐
排序字符集
utf8mb4_unicode_ci 基于标准的 Unicode 来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci 8.0前默认,有实现 Unicode 排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致
utf8mb4_0900_ai_ci 8.0后默认
uft8mb4 表示用 UTF-8 编码方案,每个字符最多占 4 个字节
0900 指的是 Unicode 校对算法版本
ai 指的是口音不敏感,也就是说,排序时 e,è,é,ê 和 ë 之间没有区别。
ci 表示不区分大小写,也就是说,排序时 p 和 P 之间没有区别
*/
库操作¶
Database is a collection of schemas and Schema is a collection of Tables. But in MySQL they use it the same way.
-- 查看有哪些库
show databases;
/*
+--------------------+
| Database |
+--------------------+
| mysql | 主要保存服务器运行时需要的系统信息,比如数据文件夹、当前使用的字符集、约束检查信息等
| information_schema | 主要保存服务器系统信息,比如数据库名、表名、字段名、存取权限等
| performance_schema | 监控各类性能指标
| sys | 以更容易理解的方式展示性能指标供开发人员监控(图形化客户端中仅显示这个)
+--------------------+
*/
-- 创建库,可以指定指定字符集和校对规则等
CREATE DATABASE <库名> -- To use this statement, you need the CREATE privilege for the database.
CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
-- CREATE SCHEMA is a synonym for CREATE DATABASE as of MySQL 5.0.2.
CREATE DATABASE <库名> -- 从 v5.0.2 开始,推荐用此语句创建库
-- 删除库
drop database if exists <库名>;
-- 使用库
use <库名>;
-- 列出当前库下所有表
show tables;
表操作¶
-- 查看表结构
describe students; -- 可简写为 desc
/*
mysql> DESCRIBE demo.test; 附加信息
+-----------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------+------+-----+---------+-------+
| barcode | text | YES | | NULL | |
| goodsname | text | YES | | NULL | |
| price | int | YES | | NULL | |
+-----------+------+------+-----+---------+-------+
3 rows in set (0.00 sec)
*/
创建表¶
CREATE TABLE <表名>
(
字段名1 数据类型 [字段级别约束] [默认值],
字段名2 数据类型 [字段级别约束] [默认值],
......
[表级别约束]
);
/*
字段名称,需要避开系统关键字,比如:key, value
默认值:DEFAULT xxx
*/
CREATE TABLE demo.importhead
(
listnumber INT,
importtype INT DEFAULT 1,
quantity DECIMAL(10,3),
recordingdate DATETIME
);
-- 复制已存在的表结构来创建新表
CREATE TABLE demo.a_copy LIKE demo.a;
CREATE TABLE demo.a_snapshot SELECT * FROM a WHERE xxx=yyy;
-- 删除表
drop table if exist <表名>;
-- 查看创建表的 SQL 语句
show create table <表名>;
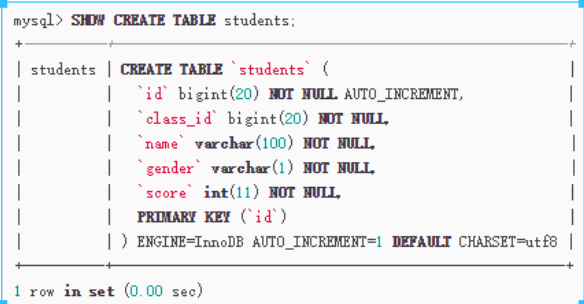
修改表¶
-- 修改表存储引擎,创建表时默认使用 INNODB 引擎
ALTER TABLE <表名> ENGINE=INNODB;
-- 修改表名
ALTER TABLE <表名> RENAME TO <新表名>;
-- 修改字段名
ALTER TABLE <表名> RENAME <旧字段名> TO <新字段名>;
-- 修改字段类型
ALTER TABLE <表名> MODIFY <字段名> float(3,1);
-- 修改字段:可以修改类型、名、约束、位置等其中一个或多个属性
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新类型、约束、位置等>;
-- 比如字段名等不变,只将字段移动到首位
ALTER TABLE <表名> CHANGE `itemnumber` `itemnumber` INT NOT NULL AUTO_INCREMENT FIRST;
-- 新增字段
ALTER TABLE <表名> ADD COLUMN <字段名> INT [FIRST / AFTER <某字段>];
/*
COLUMN 可省略
新增字段默认在最后,可以指定位置
FIRST 移到首位
AFTER 移到某字段后
*/
-- 示例,添加主键
ALTER TABLE demo.test ADD COLUMN itemnumber int PRIMARY KEY AUTO_INCREMENT;
-- 新增多个字段
ALTER TABLE <表名>
ADD COLUMN `B` TEXT NOT NULL AFTER `A`,
ADD COLUMN `C` TEXT NOT NULL AFTER `B`;
-- 删除字段
ALTER TABLE <表名> DROP <字段名>;
字段类型¶
合理的定义数据类型,可以提升数据查询和处理速度,反之可能会引发各种错误
经验:
- 确定是整数,就用 INT
- 浮点数,就用定点数类型 DECIMAL
- 字符串,只要不是主键,就用 TEXT
- 日期与时间,就用 DATETIME
整数¶
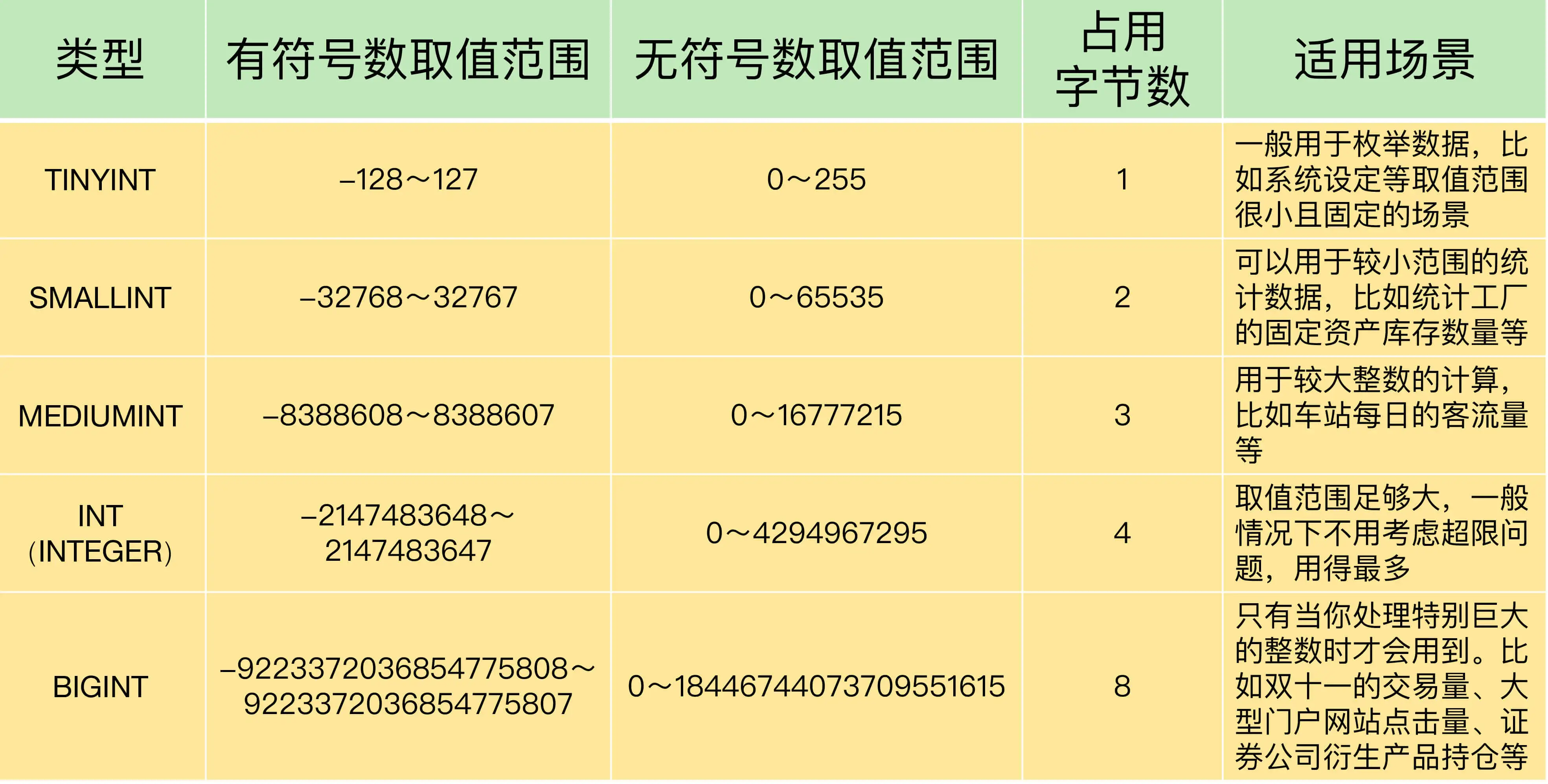
若为了节省存储空间而选用占用字节数更少的类型,一旦因取值范围而产生系统故障,则得不偿失,所以应该首先保证不会超过取值范围,其次再考虑节省空间的问题,最常用的是 INT
浮点数¶

FLOAT单精度浮点数DOUBLE双精度浮点数REAL,默认为 DOUBLE,也可以设置为 FLOAT:SET sql_mode="REAL_AS_FLOAT";
由于浮点数在计算机中需要转换为二进制形式存储,小数部分乘基取整正序,基为 2,所以尾数若不是 0 或 5,得不到整数,会有无法精准转换的问题
所以浮点数存储是不精确的,金融等对精度要求较高的场景通常使用定点数类型 DECIMAL
mysql> SELECT *
-> FROM demo.goodsmaster;
+---------+-----------+-------+------------+
| barcode | goodsname | price | itemnumber |
+---------+-----------+-------+------------+
| 0001 | 书 | 0.47 | 1 |
| 0002 | 笔 | 0.44 | 2 |
| 0002 | 胶水 | 0.19 | 3 |
+---------+-----------+-------+------------+
3 rows in set (0.00 sec)
mysql> SELECT SUM(price)
-> FROM demo.goodsmaster;
+--------------------+
| SUM(price) |
+--------------------+
| 1.0999999999999999 |
+--------------------+
定点数¶
定点数在存储时会把十进制的整数和小数部分拆分开,并转为十六进制存储,所以不会存在精度损失的问题
所以对精度要求高的业务场景通常使用 DECIMAL 类型存储,不过定点数需要更多的存储空间
-- DECIMAL(M,D) M 表示整数加小数的位数,D 表示小数的位数,所以 M>D
ALTER TABLE demo.goodsmaster MODIFY COLUMN price DECIMAL(5,2);
字符串¶
- TEXT 按照实际长度存储
- CHAR(M) 固定长度字符串
- VARCHAR(M) 可变长度字符串
- ENUM 枚举,取1个
- SET 字符串对象,取0或多个
其中 CHAR、VARCHAR 需要预先知道字符长度,SET 和 ENUM 需要预先知道所有可能的取值
TEXT 类型最为灵活和常用,但因为长度不固定所以不能作为主键
TEXT 根据长度不同又可分为

日期与时间¶
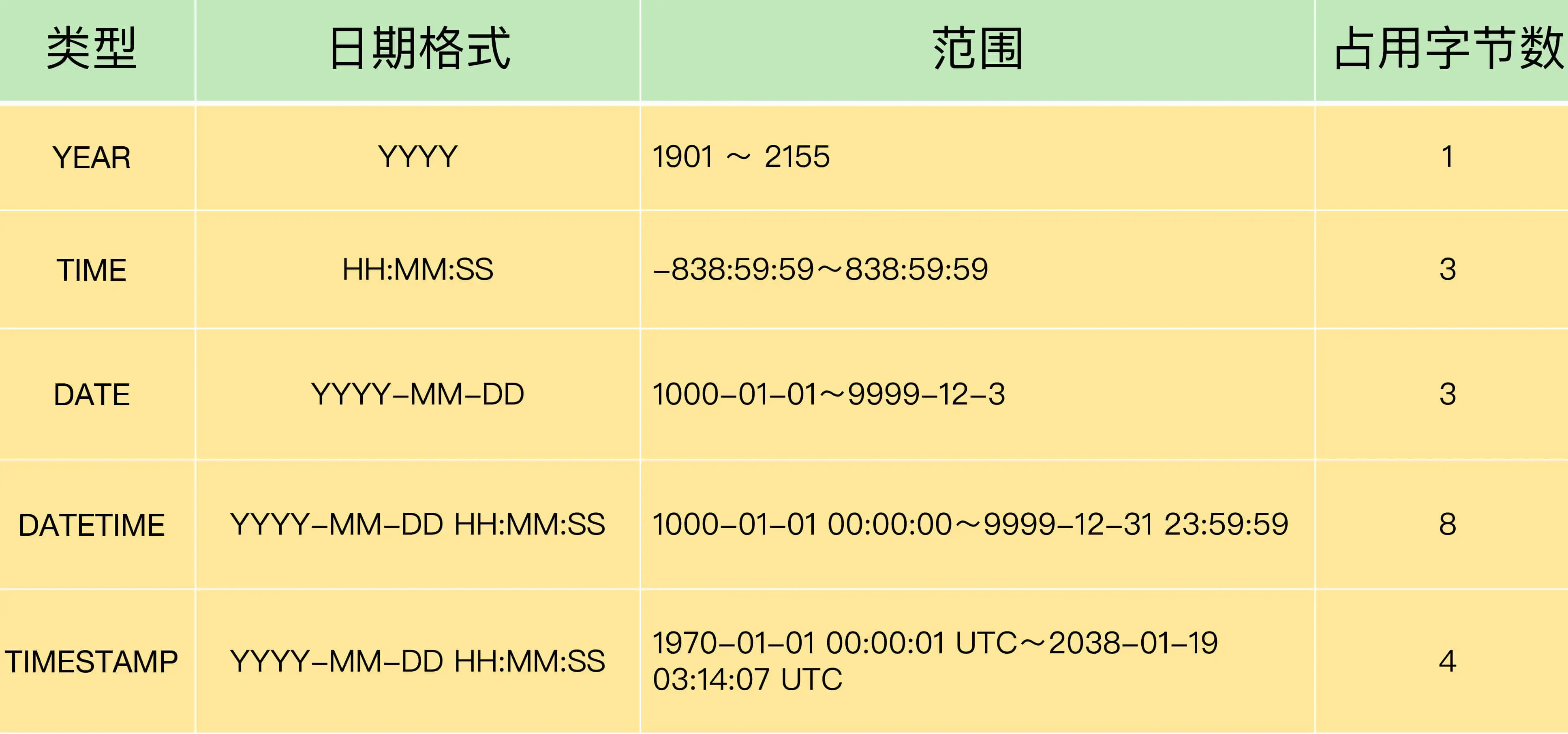
TIME 的取值范围不是 -23:59:59~23:59:59,目的是可以 TIME 来表示时间间隔,而不只是一天的时间
最常用的是 DATETIME
BOOLEAN 类型¶
用 BOOLEAN 定义布尔类型字段,实际是定义了一个 TINYINT(1),存储 0 或 1 表示假或真
NULL¶
表示字段数据不存在,通常情况下,字段应该避免允许为 NULL
不允许为 NULL 可以简化查询条件,加快查询速度,也利于应用程序读取数据后无需判断是否为 NULL
在 MySQL 中,NULL 与长度为 0 的空字符串不同,空值的长度是空,但也占用空间。
约束¶
约束限定了表中数据应该满足的条件,MySQL 会根据这些限定条件对表进行监控,阻止破坏约束条件的操作执行,并提示错误,从而确保表中的数据的唯一性、合法性、完整性。
默认值约束¶
DEFAULT xxx
非空约束¶
NOT NULL
即是否允许空值
默认允许,空值 NULL 也占用空间,空字符串长度是0,不属于空值
唯一性约束¶
UNIQUE
即字段的值不能重复,可以指定多个唯一性字段,但主键只能有一个
满足唯一性约束的字段,可以是空值,但满足主键约束的字段,自动满足非空约束
自增约束¶
AUTO_INCREMENT
可以被设置自增约束的字段必须是整数类型
可以给自增字段设置值,值可以不连续,若没设置值的时候,会在已有的最大值基础之上自动 +1 作为值
通常需要跟唯一约束或主键约束一起使用,为了确保自增字段的唯一性,MySQL 8.0 引入了更严格的自增锁机制,使得在并发插入时更少发生自增值重复的问题。
主键约束¶
PRIMARY KEY,俗称 PK 或 PRI
-- 删除主键约束(不会删除字段)
ALTER TABLE demo.test
DROP PRIMARY KEY;
主键用于唯一标识表中的某一条记录,不能为空值,可以是一个字段也可以是多个字段的组合(联合主键)
一个表只能有一个主键,有三种设置方式
- 业务字段做主键:用商品号、身份证、手机号等看起来唯一的业务字段做主键,简单快捷,但是比较容易有隐藏的问题,比如手机号可能会变更使用者
- 自增字段做主键:单机系统时没有问题,但多台服务分布式管理时会出问题,比如一家连锁店,各个店铺分别创建会员然后定期同步给总店,id可能会重复,就会有冲突
- 手动赋值做主键:稍微麻烦一些,但是避免了未来业务扩增或者无法预测的问题
B+ 树为了维护索引有序性,在插入新值时,可能会涉及挪动以及新增数据页,所以从性能和存储空间方面考量,如果表有多个索引字段,建议使用自增主键,当只有一个索引且必须是唯一索引时,才适合考虑用业务字段做主键。
外键约束¶
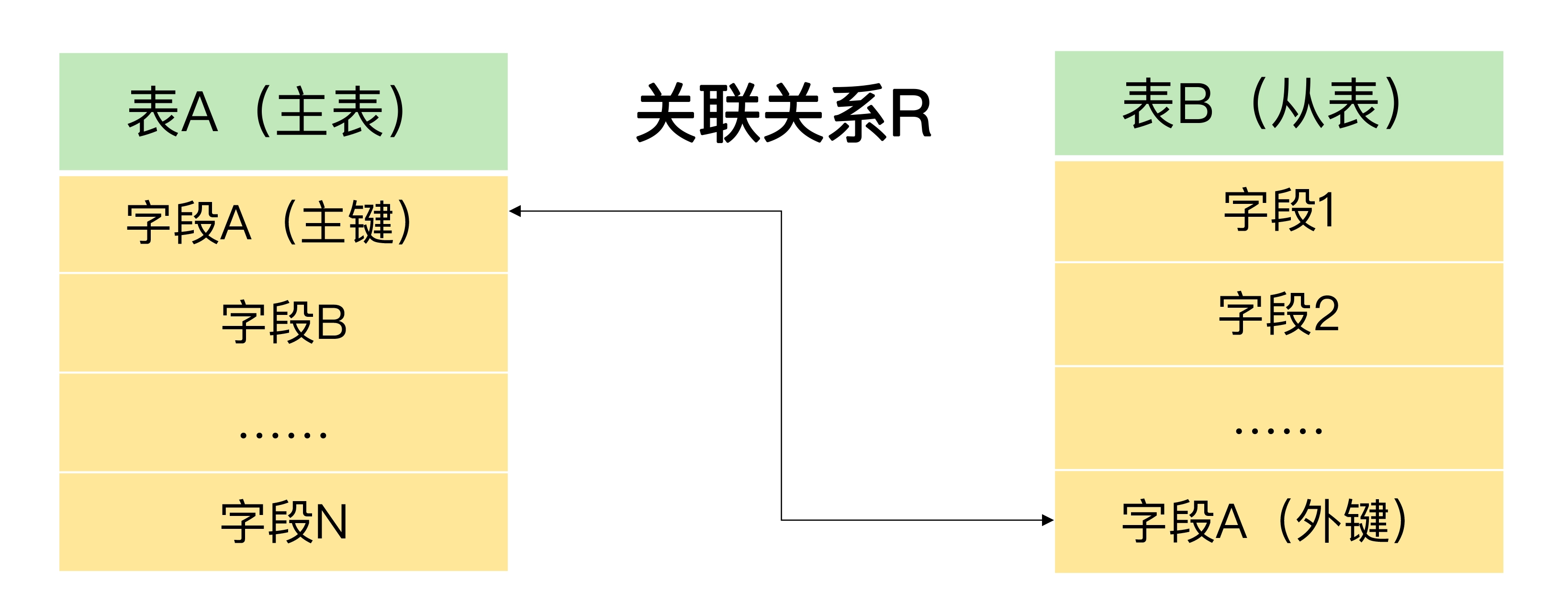
表B的某个字段引用了表A的某个主键字段,则这个字段被称之为外键,即表B通过外键与表A建立了一个关系R,表A被称作主表,表B被称之为从表。
CREATE TABLE 从表B -- table_name
(
...
-- 定义外键约束,指出外键字段和参照的主表字段
CONSTRAINT 外键约束名 -- constraint_name
FOREIGN KEY (字段名) -- column_name
REFERENCES 主表A (字段名) -- referenced_table_name referenced_column_name
...
)
-- 举例:importdetails的listnumber字段引用了importhead的listnumber字段
CONSTRAINT fk_importdetails_importhead
FOREIGN KEY (listnumber)
REFERENCES importhead (listnumber)
外键可以为空,也可以重复,因此多表之间的关系可以有如下几种
- 一对一
- 一对多
- 多对多
外键约束可以保护数据误删的情况,但也比较消耗系统资源,在高并发或者大型互联网项目中,通常会降低外键约束的使用,而是转移到业务层来实现,比如删除主表记录时,增加检查从表中是否应用了这条记录的功能,如果应用了,就不允许删除。