事务¶
https://www.liaoxuefeng.com/wiki/1177760294764384/1179611198786848
所谓的事务(transaction),就是把多条语句作为一个整体进行操作,这些操作要么全部成功,要么全部失败,是一个不可分割的集合。
ACID 特性¶
事务具有 ACID 4 个特性:
AID 是实现一致性(C)这个目标的手段
- Atomicity 原子性,将所有SQL作为原子工作单元执行,要么全都执行,要么全不执行;
- Consistency 一致性,事务完成后,所有数据的状态都是一致的,即 A 账户只要减去了100,B 账户则必定加上了 100;
- Isolation 隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
- Durability 持久性,即事务完成后,对数据库数据的修改被持久化存储,不会再因为任何原因而导致其修改的内容被撤销或丢失。
显式事务¶
单条 SQL 语句,其实也是作为一个事务被执行的,属于数据库系统默认的行为,这种事务被称为「隐式事务」
而通常我们所说的事务是「显式事务」
BEGIN; -- 开启事务,或者 start transaction
UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- user1 的余额 -100
UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- user2 的余额 +100
COMMIT; -- 提交事务,失败会回滚
-- 可以主动让事务失败回滚
ROLLBACK
有些客户端连接框架会默认连接成功后先执行一个 set autocommit=0 的命令,则不再需要 begin 显示启动事务,但这样会导致事务不再自动 commit,遇到长连接,就会一直处于同一个长事务中。
要避免使用长事务,除了占用锁资源,产生的回滚日志会占用大量存储空间。
-- 查找持续时间超过 60s 的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
每条记录在更新的时候都会同时记录一条回滚操作,假设一个值从 1 被按顺序改成了 2、3、4,就会有类似下面的回滚日志记录
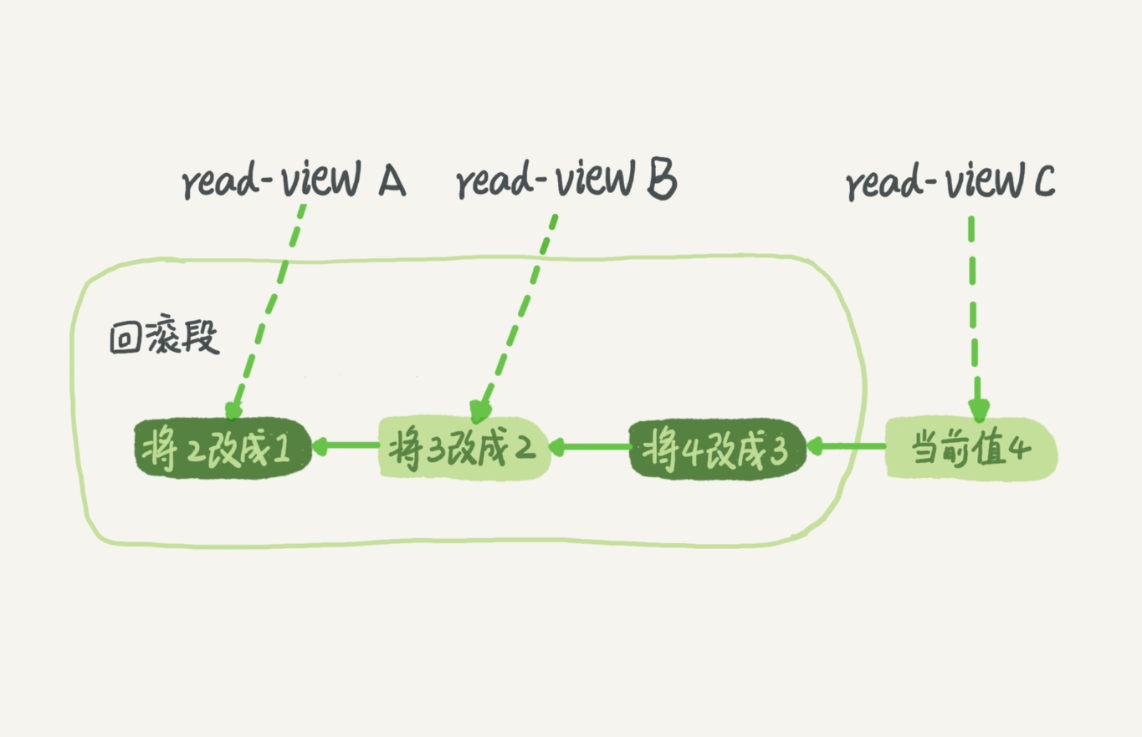
即同一条记录在系统中可以存在多个版本,也就是数据库的多版本并发控制(MVCC),可以将值从 4 依次回滚到 1。
当没有事务再需要用到这些回滚日志时,回滚日志才会被删除。
隔离级别¶
当数据库上有多个事务同时执行的时候,就可能出现脏读、不可重复读、幻读的问题,为了解决这些问题,就有了「隔离级别」的概念。

SQL 标准定义了 4 种隔离级别,不同隔离级别下 V1,2,3 读到的值是不一样的
读未提交 Read Uncommitted
事务 B 还没有提交时,变更结果就可以被事务 A 读到,所以 V1=V2=V3=2
读提交 Read Committed
事务 B 提交后,变更结果才可以被事务 A 读到,所以 V1=1, V2=V3=2
可重复读 Repeatable Read
事务在执行期间所看到的数据,前后总是一致的,即事务 A 提交前读到的值都一样,所以 V1=V2=1, V3=2
另外,对其他事务也是不可见的。
适用场景:比如计算上个月余额和当前余额的差值,是否与本月的账单明细一致,这个过程中若不希望用户的新交易影响校对结果,就需要使用可重复读隔离级别。
串行化 Serializable
读或写同一行记录时,会加读锁或写锁。后访问的事务必须等前一个事务执行完成,才能继续执行。
事务 B 将值从 1 修改到 2 时,会加写锁,作为后执行的事务,需要等待事务 A 提交后才可以继续执行。所以 V1=V2=1, V3=2
从视图的角度来理解不同隔离级别
读未提交,直接返回记录上的最新值,没有视图的概念
读提交,SQL 语句开始执行时创建视图
可重复读,事务启动时会创建视图,整个事务存在期间都用这个视图
串行化,使用加锁的方式避免并行访问
Oracle 默认的隔离级别是「读提交」,InnoDB 默认的隔离级别是「可重复读」,所以跨数据库迁移时一定要保证隔离级别一致
-- 查看当前事务隔离级别
SHOW VARIABLES LIKE 'transaction_isolation';
SHOW VARIABLES LIKE 'tx_isolation'; -- v8.0+
-- 查看全局事务隔离级别
SHOW GLOBAL VARIABLES LIKE 'tx_isolation';
-- 设置当前会话隔离级别
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 设置全局隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
不同隔离级别会产生的问题

- 脏读(Dirty Read),一个事务会读到另一个事务未提交的更新,如果另一个事务回滚,那么当前事务读到的数据就是脏数据。
- 不可重复读(Non-Repeatable Read),在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
- 幻读(Phantom Read),在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
锁¶
数据库锁设计的初衷是处理并发问题
根据加锁的范围,MySQL 里面的锁大致可以分成:全局锁、表级锁、行锁
全局锁¶
全局锁就是对整个数据库实例加锁,MySQL 提供了一个加全局读锁的方法,命令是: Flush tables with read lock(FTWRL)
此时数据库将变为只读状态,所有更新数据库的操作都会被阻塞,通常用于数据库逻辑备份时
如果数据库引擎支持隔离级别,则这个场景使用可重复读隔离级别事务是更友好,因为备份期间仍可以更新数据库,并且可以保持数据一致性,比如官方自带的逻辑备份工具 mysqldump 就是这样做的
表级锁¶
表锁一般是在数据库引擎不支持行锁的时候才会被用到(比如 MyISAM),同一张表上任何时刻只能有一个更新在执行,会影响到业务并发度
- 表锁
-- 线程 A 中执行,t1 设为读锁,t2 设为写锁
lock tables t1 read, t2 write;
-- 持有读锁的线程(线程 A)可以读取表 t1 的数据,其他线程在这个读锁期间不能对 t1 进行写入操作,但可以读取
-- 持有写锁的线程(线程 A)可以对表 t2 进行读写操作,其他线程在这个写锁期间不能对 t2 进行任何操作,包括读取和写入
-- 解锁
unlock tables
-- 如果线程 A 没有显式地解锁,将保持到连接关闭
- 元数据锁(meta data lock,MDL)
MDL 不需要显式使用,在访问一个表的时候系统默认自动加的,在 MySQL 5.5 版本中引入
当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
所有对表的增删改查操作都需要先申请 MDL 读锁,说要要避免长事务,因为事务不提交就会一直占用 MDL 锁,导致线程爆掉
行级锁¶
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放,这个就是两阶段锁协议。
所以如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
1. 从顾客 A 账户余额中扣除电影票价
2. 给影院 Y 的账户余额增加这张电影票价
3. 记录一条交易日志
比如上述场景,需要放到一个事务中执行,考虑到还会有其他顾客购买影票
那么会产生冲突的语句就是 2,所以应该把操作 2 加行级锁并放到最后,即:3->1->2,来减少事务间的锁等待,提升并发度
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会出现死锁
比如下图,事务 A 在等待事务 B 释放 id=2 的行锁
事务 B 在等待事务 A 释放 id=1 的行锁,就进入了死锁状态

出现死锁有两种策略
- 策略1,进入等待,直到超时
innodb_lock_wait_timeout 的默认值是 50s,这对于线上服务是无法接受的,但若改小这个值,又会影响正常的等待
- 策略2,发起死锁检测,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行
将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑
但如果线程过多,死锁检测要消耗大量的 CPU 资源,导致每秒执行不了几个事务
所以要控制并发度,而且不能只在客户端上去控制,因为客户端的数量不确定,即使每个客户端控制几个,多个客户端加起来也会有很多,所以最好是在服务端去控制,如果有中间件,可以考虑在中间件实现,基本思路就是,对于相同行的更新,在进入引擎之前排队。这样在 InnoDB 内部就不会有大量的死锁检测工作了。