引言¶
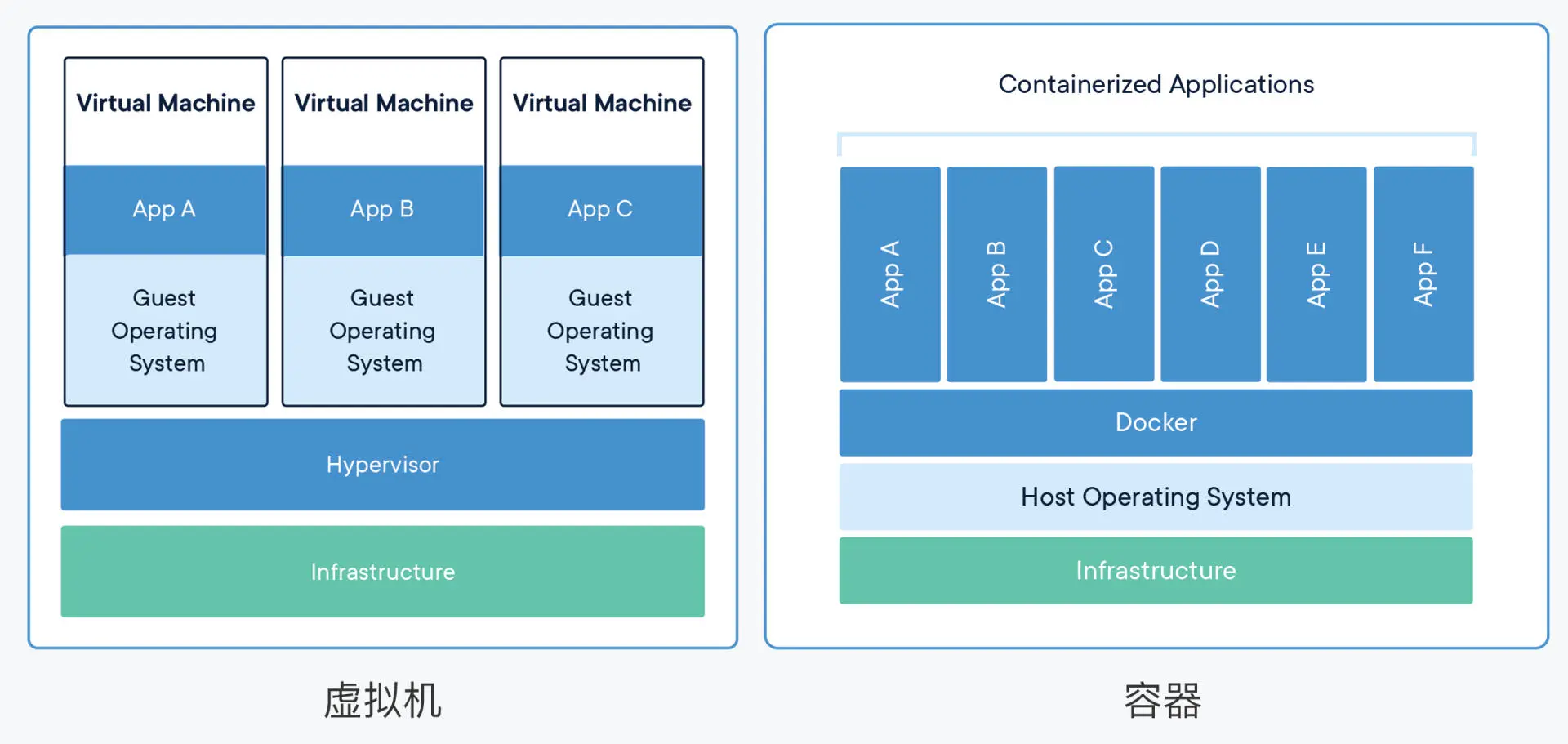
虚拟机使用了Hypervisor硬件虚拟化技术,虚拟出包括操作系统在内的整个沙盒环境,比较消耗资源
而容器利用了Linux内核提供的几种技术:namespace(内核命名空间)、cgroup(控制资源的)、rootfs等,仅仅是隔离出一个独立的进程,与宿主机共享内核,性能更好。
安装¶
使用Docker有两种选择:Docker Engine 和 Docker Desktop
Docker Desktop for Windows/Mac 本质上是基于Hyper-V等虚拟机安装的,类似于在 VMWare 或 VirtualBox中安装。
Docker必须部署在Linux内核的系统上,因为容器没有虚拟化内核,而是与宿主机共用内核
容器中安装的各种操作系统镜像其实只是套了壳的软件而已,并不是真正的操作系统。
凡是挑内核的场景都不适用于使用Docker,比如不能做系统兼容性测试,也不能在Docker环境中驱动IE浏览器。
所以并不推荐使用Docker Desktop,另一个原因是它属于商业化产品,有一些非通用的东西,而仅适用于Linux的Docker Engine是完全免费开源的,也是Kubernetes的基石之一
# Ubuntu
# https://docs.docker.com/engine/install/ubuntu/
# 移除各种旧版本
sudo apt-get remove docker docker-engine docker.io containerd runc
# 设置存储库
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 安装
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
# 测试
sudo docker run hello-world
# ubuntu安装完会自启动
sudo systemctl start docker
# 开机自启动
sudo systemctl enable docker
# 操作Docker必须要有root权限
# 推荐将当前用户加入docker组(需要exit重新登录后生效)
sudo usermod -aG docker ${USER}
基本命令¶
docker # 查看所有命令选项
docker <command> --help # 查看命令使用帮助
docker version # 版本信息
docker info # 系统信息
'''
Server:
Containers: 1
Running: 0
Paused: 0
Stopped: 1
Images: 8
Server Version: 20.10.12
Storage Driver: overlay2 # 存储用的文件系统
Backing Filesystem: extfs
Cgroup Driver: systemd
Default Runtime: runc
Kernel Version: 5.13.0-19-generic # Linux内核
Operating System: Ubuntu Jammy Jellyfish (development branch) # 操作系统
OSType: linux
Architecture: aarch64 # 硬件
CPUs: 2
Total Memory: 3.822GiB # 内存
Docker Root Dir: /var/lib/docker
'''
概念¶
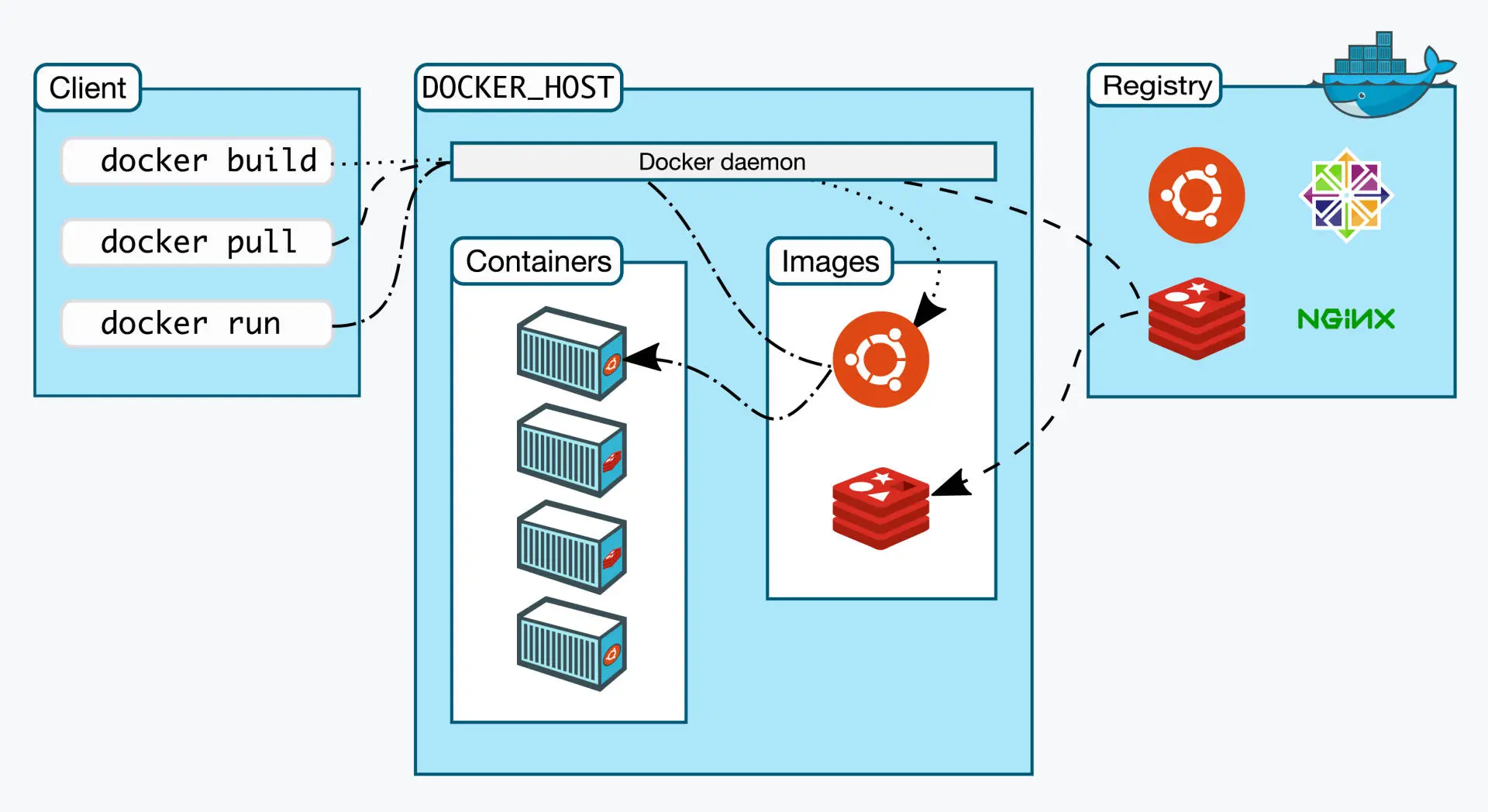
- 镜像仓库(Registry):管理镜像的仓库,类似代码库 GitHub
- 镜像(Images):包含运行软件所需的一切要素(代码和运行时)
- 容器(Container):镜像的实例,每一个 Docker 容器都拥有自己的文件系统、网络体系(因此也拥有自己的 IP 地址)、进程空间以及面向 CPU 和内存定义的资源限制。同时,它不需要引导操作系统,可以即时启动。简而言之,Docker 的宗旨是隔离,即隔离主机操作系统的资源,虚拟化则是在主机操作系统上提供访客操作系统。
- 编排(Compose):使用YAML文件同时编排多个容器
原理¶
Docker 创建的一个容器初始化进程 (dockerinit) 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。
最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
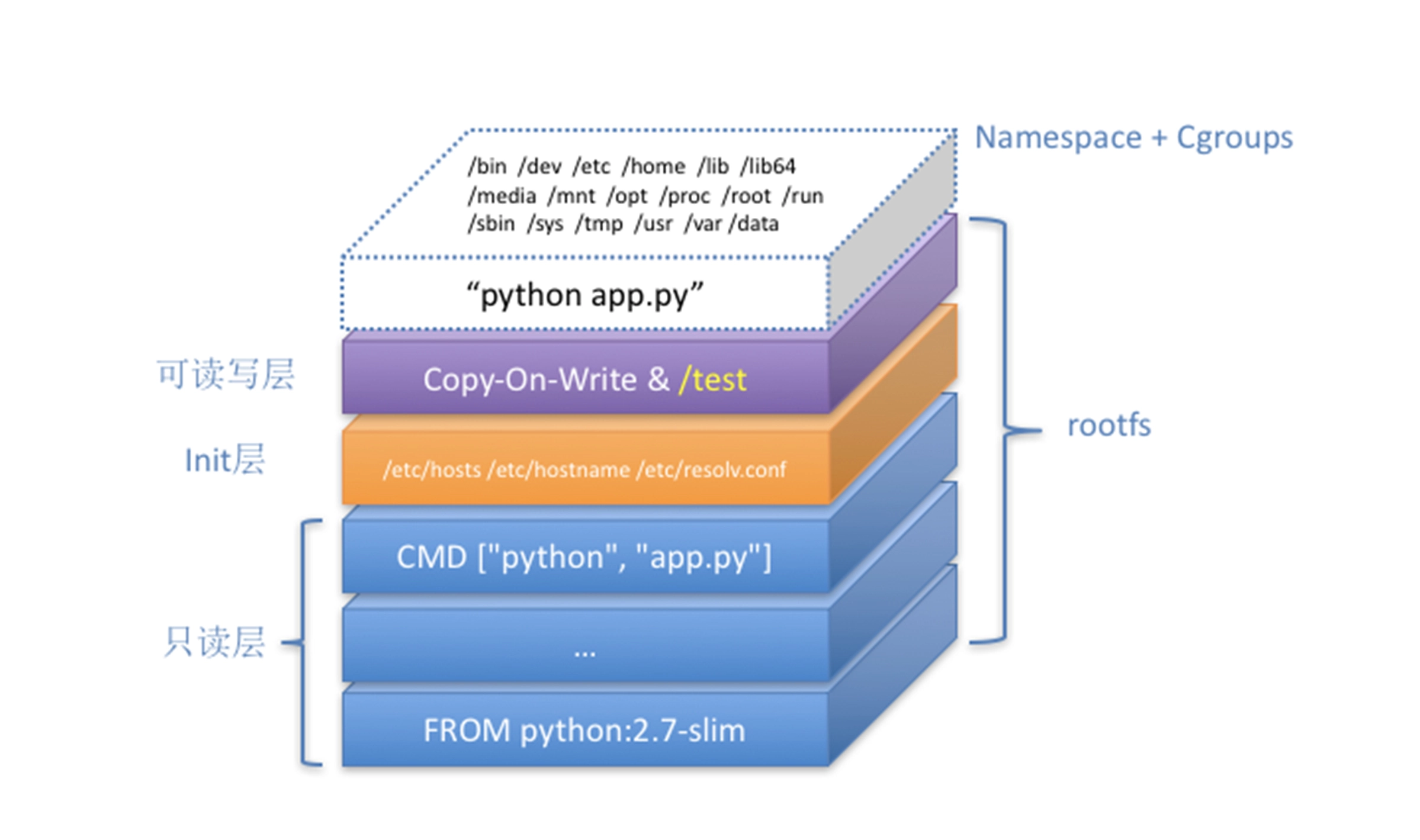
这个容器进程“python app.py”,运行在由 Linux Namespace 和 Cgroups 构成的隔离环境里;而它运行所需要的各种文件,比如 python,app.py,以及整个操作系统文件,则由多个联合挂载在一起的 rootfs 层提供。这些 rootfs 层的最下层,是来自 Docker 镜像的只读层。在只读层之上,是 Docker 自己添加的 Init 层,用来存放被临时修改过的 /etc/hosts 等文件。而 rootfs 的最上层是一个可读写层,它以 Copy-on-Write 的方式存放任何对只读层的修改,容器声明的 Volume 的挂载点,也出现在这一层。
namespace¶
命名空间有很多种,分别用于隔离不同的东西
查看内核支持的Namespace:
ls -l /proc/self/s
- PID Namespace
- Mount Namespace
- Network Namespace
# 容器在宿主机上是一个真实存在的进程
docker inspect --format '{{ .State.Pid }}' <容器ID>
# 查看容器所有 Namespace 对应的文件
ls -l /proc/<容器pid>/ns
# 指定–net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。
docker run -it --net container:4ddf4638572d busybox ifconfig
cgroup¶
Linux Control Group 最初由Google实现,被用于Borg系统(Kubernetes的前身),后被集成进Linux内核。
它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,cgroup 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
对于 Linux 系统而言,容器就是一组进程的集合。如果容器中的应用创建过多的进程或者出现 bug,就会产生类似 fork bomb 的行为。
fork bomb 指在计算机中,通过不断建立新进程来消耗系统中的进程资源,它是一种黑客攻击方式。这样,容器中的进程数就会把整个节点的可用进程总数给消耗完。
这样,不但会使同一个节点上的其他容器无法工作,还会让宿主机本身也无法工作。所以对于每个容器来说,我们都需要限制它的最大进程数目,而这个功能由 pids Cgroup 这个子系统来完成。
pids Cgroup 通过 Cgroup 文件系统的方式向用户提供操作接口,在一个容器建立之后,创建容器的服务会在挂载点 /sys/fs/cgroup/pids 下建立一个子目录,就是一个控制组,控制组里最关键的一个文件就是 pids.max。我们可以向这个文件写入数值(即容器中允许的最大进程数目)。
容器是一个“单进程”模型,在一个容器中,你没办法同时运行两个不同的应用,跟 Namespace 的情况类似,cgroup 对资源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系统的问题。
如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。造成这个问题的原因就是,/proc 文件系统并不知道用户通过 cgroup 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 cgroup 限制的存在。
分层结构¶
通过结合使用 Mount Namespace 和 rootfs,容器就能够为进程构建出一个完善的文件系统隔离环境。当然,这个功能的实现还必须感谢 chroot 和 pivot_root 这两个系统调用切换进程根目录的能力。而在 rootfs 的基础上,Docker 公司创新性地提出了使用多个增量 rootfs 联合挂载一个完整 rootfs 的方案,这就是容器镜像中“层”的概念。
通过“分层镜像”的设计,以 Docker 镜像为核心,来自不同公司、不同团队的技术人员被紧密地联系在了一起。而且,由于容器镜像的操作是增量式的,这样每次镜像拉取、推送的内容,比原本多个完整的操作系统的大小要小得多;而共享层的存在,可以使得所有这些容器镜像需要的总空间,也比每个镜像的总和要小。这样就使得基于容器镜像的团队协作,要比基于动则几个 GB 的虚拟机磁盘镜像的协作要敏捷得多。更重要的是,一旦这个镜像被发布,那么你在全世界的任何一个地方下载这个镜像,得到的内容都完全一致,可以完全复现这个镜像制作者当初的完整环境。这,就是容器技术“强一致性”的重要体现。
发展¶
参考自极客时间《深入剖析Kubernetes》:https://time.geekbang.org/column/intro/100015201?tab=catalog
从过去以物理机和虚拟机为主体的开发运维环境,向以容器为核心的基础设施的转变过程,并不是一次温和的改革,而是涵盖了对网络、存储、调度、操作系统、分布式原理等各个方面的容器化理解和改造。
就在这场因“容器”而起的技术变革中,Kubernetes 项目已然成为容器技术的事实标准,重新定义了基础设施领域对应用编排与管理的种种可能。
2013年,虚拟机和云计算已经是比较普遍的技术和服务了,那时主流用户的普遍用法,就是租一批 AWS 或者 OpenStack 的虚拟机,然后像以前管理物理服务器那样,用脚本或者手工的方式在这些机器上部署应用。
当然,这个部署过程难免会碰到云端虚拟机和本地环境不一致的问题,所以当时的云计算服务,比的就是谁能更好地模拟本地服务器环境,能带来更好的“上云”体验。以 Cloud Foundry 为主的 PaaS 开源项目的出现,就是当时解决这个问题的一个最佳方案。
PaaS 之所以能够帮助用户大规模部署应用到集群里,是因为它提供了一套应用打包的功能。可偏偏就是这个打包功能,却成了 PaaS 日后不断遭到用户诟病的一个“软肋”。出现这个问题的根本原因是,一旦用上了 PaaS,用户就必须为每种语言、每种框架,甚至每个版本的应用维护一个打好的包。这个打包过程,没有任何章法可循,更麻烦的是,明明在本地运行得好好的应用,却需要做很多修改和配置工作才能在 PaaS 里运行起来。而这些修改和配置,并没有什么经验可以借鉴,基本上得靠不断试错,直到你摸清楚了本地应用和远端 PaaS 匹配的“脾气”才能够搞定。最后结局就是,“cf push”确实是能一键部署了,但是为了实现这个一键部署,用户为每个应用打包的工作可谓一波三折,费尽心机。
而就在这时,一个并不引人瞩目的 PaaS 创业公司 dotCloud,却选择了开源自家的一个容器项目 Docker。更出人意料的是,就是这样一个普通到不能再普通的技术,却开启了一个名为“Docker”的全新时代。
Docker 项目确实与 Cloud Foundry 的容器在大部分功能和实现原理上都是一样的,可偏偏就是这剩下的一小部分不一样的功能,成了 Docker 项目接下来“呼风唤雨”的不二法宝。这个功能,就是 Docker 镜像。而 Docker 镜像解决的,恰恰就是打包这个根本性的问题。
Docker 项目给 PaaS 世界带来的“降维打击”,其实是提供了一种非常便利的打包机制。这种机制直接打包了应用运行所需要的整个操作系统,从而保证了本地环境和云端环境的高度一致,避免了用户通过“试错”来匹配两种不同运行环境之间差异的痛苦过程。
Docker 项目固然解决了应用打包的难题,但它并不能代替 PaaS 完成大规模部署应用的职责。用户们最终要部署的,还是他们的网站、服务、数据库,甚至是云计算业务。这就意味着,只有那些能够为用户提供平台层能力的工具,才会真正成为开发者们关心和愿意付费的产品。
容器本身没有价值,有价值的是容器编排,正因为如此,容器技术生态才爆发了一场关于容器编排的战争。
Kubernetes 凭借Google和CNCF社区的强力背书。击败了Docker Swarm 和Apache Mesos等对手,成为云原生操作系统的事实标准,而Docker Engine这样一个只能用来创建和启停容器的小工具,最终只能充当这些平台项目的幕后英雄。