算法复杂度分析¶
在算法设计中,首先要找到问题的解法,然后寻求既快又省的最优解法
- 快,时间效率,算法运行的快慢
- 省,空间效率:算法占用内存空间的大小
动态分析法:实际测试¶
测试结果受数据规模影响较大,且依赖测试环境,比如同一算法在不同的硬件配置下可能性能不一致。
time
import time
start_time = time.time() # 开始时间
pass # 待测算法
end_time = time.time() # 结束时间
print(end_time - start_time) # 耗时
timeit
timeit.timeit(stmt, setup, timer, number)
"""
stmt: 语句,statement的缩写,要测试的代码或者语句,默认值是"pass"
setup: 在运行stmt前的配置语句,默认值"pass"
timer: 计时器,一般忽略这个参数
number: 语句的执行次数,默认100万次
"""
# 由于stmt只能是语句,需要借助匿名函数来测试函数
t = timeit.timeit(lambda:range(10), number=500)
print(t)
静态分析法:理论估算¶
渐近复杂度分析(Asymptotic Complexity Analysis),描述了随着输入数据大小的增加,算法执行所需时间和空间的增长趋势,关注的不是运行时间或占用空间的具体值,而是时间或空间增长的快慢,反映了算法运行效率与输入数据体量之间的关系。
- 时间复杂度(Time Complexity)
- 空间复杂度(Space Complexity)
时间复杂度分析本质上是计算操作数量的渐近上界(asymptotic upper bound)
设算法的操作数量是一个跟输入数据规模 \(n\) 相关的函数,记为 \(T(n)\)
- 数据规模:\(n\)
- 代码总执行次数:\(f(n)\)
- 每行代码执行时间:\(t\)
- 代码总执行时间:\(T(n) = f(n) * t\)
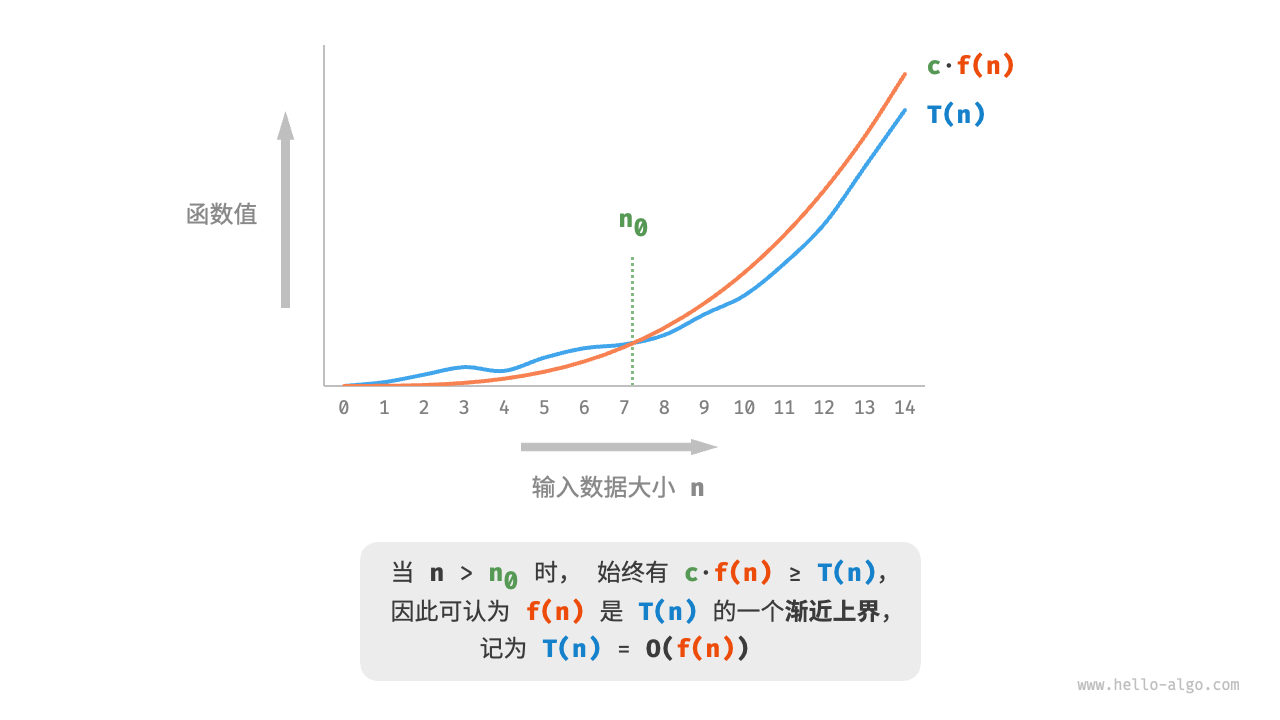
在不运行代码的情况下,假设 \(t\) 相同,\(n\) 趋向无穷,则常量系数、低阶、底阶等对增长趋势的影响都可以忽略,即:T(n) = O(f(n))

大 \(O\) 记号(big-notation)\(O(n)\) 称作 \(T(n)\) 的渐进上界,也叫大 \(O\) 复杂度
准确来讲,函数渐近上界对应的是最差时间复杂度,用符号 \(O(n)\) 表示,渐近下界对应最佳时间复杂度,用 \(\Omega(n)\) 表示,平均时间复杂度用 \(\Theta(n)\) 表示
最差和最佳通常只出现在特殊的数据分布中,而平均复杂度虽然比较真实,但需要假设输入是均匀分布的,计算比较复杂,所以虽然平均时间复杂度更有意义,但关注和实际计算的其实是最差复杂度。
空间复杂度的推算方法与时间复杂度大致相同,统计对象变成了使用空间大小,而且我们通常只关注最差空间复杂度,因为需要确保所有输入数据都有足够的内存空间预留。
在实际情况中,同时优化时间复杂度和空间复杂度是矛盾且困难的,大多数情况下,都需要以空间换时间。
分析方法¶
- 找循环次数最多的代码段
def test():
sum = 0 # t
i = 1 # t
while i <= n: # nt
sum = sum + i # nt
i = i + 1 # nt
return sum
# T(n) = (2+3n)t
# 时间复杂度:O(n)
- 找嵌套最多,量级最大的那一段代码
def test():
sum = 0 # t
i = 1 # t
while i <= n: # nt
j = 1 # nt
while j <= n: # n^2t
sum = sum + i * j # n^2t
j = j + 1 # n^2t
return sum
# T(n) = (2+2n+3n^2)t
# 时间复杂度:O(n^2)
- 若最大有多段则相加,有嵌套则相乘
def f1(n):
ret = 0
i = 1
while i < n:
ret = ret + f2(i) # 这里调用了另一个函数f2
n = n + 1
def f2(n):
sum = 0
i = 1
while i < n:
sum = sum + i
return sum
# T(n) = T1(n) * T2(n)
# 时间复杂度为:O(n^2)
时间复杂度¶
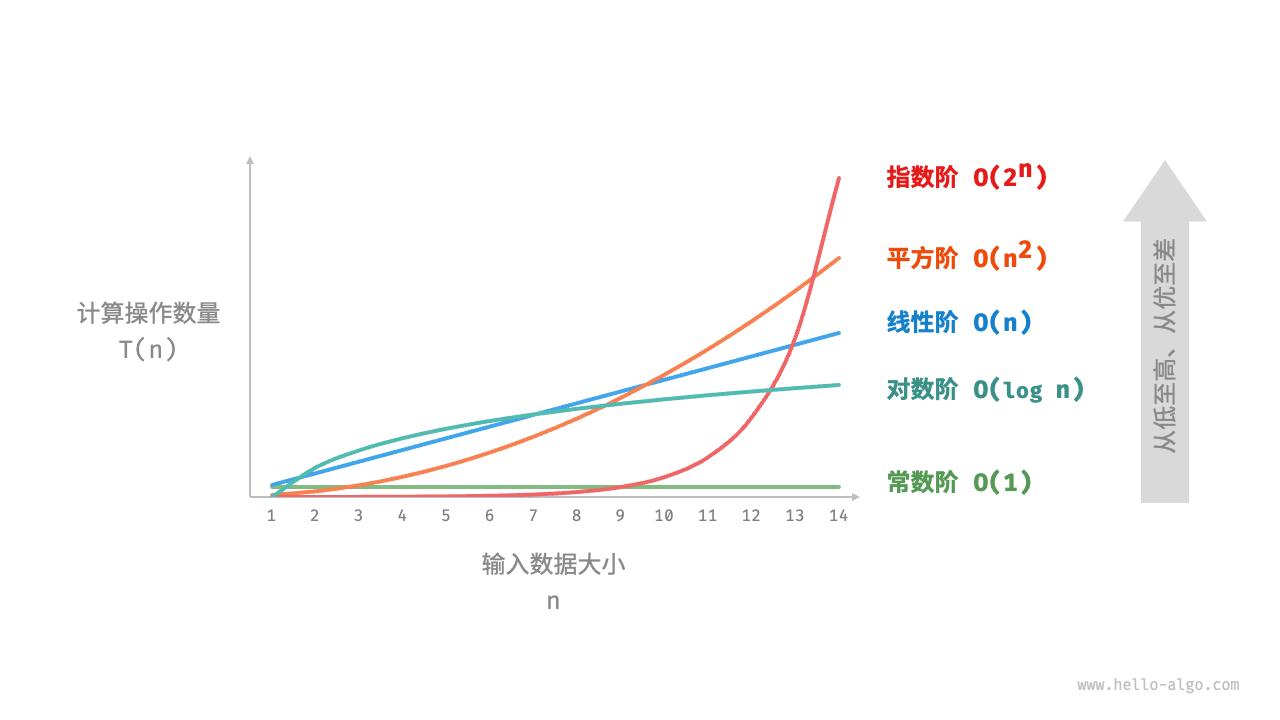
\(O(1)\) < \(O(logn)\) < \(O(n)\) < \(O(nlogn)\) < \(O(n^2)\) < \(O(2^n)\) < \(O(n^!)\)
常数阶¶
只要算法中不存在循环或递归语句,无论有多少行代码,都属于常数阶,即使有循环,但循环次数与输入数据大小无关,也属于常数级
def constant(n: int) -> int:
count = 0
for _ in range(100000):
count += 1
return count
# 循环次数与传入参数n无关,复杂度:O(1)
线性阶¶
通常出现在单层循环中,循环次数与输入大小呈线性关系
def linear(n: int) -> int:
count = 0
for _ in range(n):
count += 1
return count
平方阶¶
通常出现在嵌套循环中,比如冒泡排序
def bubble_sort(nums: list[int]) -> int:
count = 0 # 计数器
# 外循环:未排序区间为 [0, i]
for i in range(len(nums) - 1, 0, -1):
# 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j in range(i):
if nums[j] > nums[j + 1]:
# 交换 nums[j] 与 nums[j + 1]
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 元素交换包含 3 个单元操作
return count
"""
外循环:n - 1
内循环:n/2
相乘后复杂度为:O(n^2)
"""
指数阶¶
常见于递归函数、穷举法(暴力搜索、回溯等),指数阶增长非常迅速,对于数据规模较大的问题是不可接受的,通常需要使用动态规划或贪心算法等来解决
# 细胞分裂
def exponential(n: int) -> int:
count = 0
base = 1
# 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
for _ in range(n):
for _ in range(base):
count += 1
base *= 2
return count
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
对数阶¶
与指数阶相反,对数阶反映了每轮缩减到一半的情况
对数阶常出现于基于分治策略的算法中,体现了一分为多和化繁为简的算法思想。它增长缓慢,是仅次于常数阶的理想的时间复杂度。
def logarithmic(n: float) -> int:
count = 0
while n > 1:
n = n / 2
count += 1
return count
线性对数阶¶
快速排序、归并排序、堆排序等主流排序算法的时间复杂度通常都为 \(O(nlogn)\)
def linear_log_recur(n: float) -> int:
if n <= 1:
return 1
count: int = linear_log_recur(n // 2) + linear_log_recur(n // 2)
for _ in range(n):
count += 1
return count
阶乘阶¶
\(O(n^!)\)
def factorial_recur(n: int) -> int:
"""阶乘阶(递归实现)"""
if n == 0:
return 1
count = 0
# 从 1 个分裂出 n 个
for _ in range(n):
count += factorial_recur(n - 1)
return count
最好最坏时间复杂度¶
# 在一个长度不固定的无序列表中,查找元素x所在的位置
# 找到则停止查找,遍历完后没找到则返回-1
def find(_list, x):
pos = -1
for i in len(_list):
if _list[i] == x:
pos = i
break
return pos
在示例中,要查找的元素x,可能会出现在列表的任意位置,亦或者不在列表中,共有 \(n+1\) 种情况,于是复杂度需要根据不同情况进行分析:
- 如果 \(x\) 位于首位,则时间复杂度为 \(\Omega(1)\),称之:
最佳时间复杂度 - 如果 \(x\) 位于末位,则时间复杂度为 \(O(n)\),称之:
最差时间复杂度 - 但大多数情况下元素都不位于首位或末位,于是我们需要引出:
平均时间复杂度
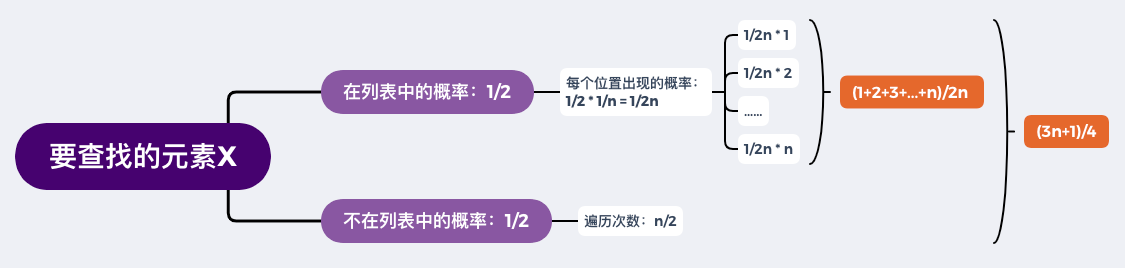
假设元素x在列表中和不在列表中的概率各自为 \(1/2\),如果在列表中,则每个位置的概率相等,均为 \(1/2 * 1/n\),即 \(1/2n\)
总遍历次数,即加权平均值为:\((1+2+3+...+n)/2n + n*1/2\),前 n 项和为:\(n(1+n)/2\),最后:\(T(n)=(3n+1)/4\),忽略系数等,最终的平均时间复杂度为:\(\Theta(n)\)
均摊时间复杂度¶
# 向一个长度为n的列表中插入新数据value,如果列表有剩余空间,则直接插入
# 如果列表没有剩余空间,则先计算其元素总和sum,然后清空列表后将sum插入到列表的首位,再继续插入value
_list = [1,2,3...n]
count = 0
def insert(value):
if count == len(_list):
sum = 0
for i in len(_list):
sum = sum + _list[i]
_list.insert(0, sum)
count = 1
_list.insert(count, value)
count = count + 1
在示例中,根据不同情况分析:
- 理想的情况下,列表有剩余空间,直接插入即可,即最佳时间复杂度为 \(\Omega(1)\)
- 最差的情况下,没有剩余空间,需要遍历一次列表求和,所以最差时间复杂度为 \(O(n)\)
- 平均情况呢?
对于该示例来说,列表要么有剩余,要么没有剩余,只有这两种情况,而且有剩余空间的概率远大于没有剩余空间的情况,我们没必要再计算其加权平均值,也就是说绝大多数情况都属于理想的情况,复杂度都是 \(\Theta(1)\),称之为均摊时间复杂度,算是平均情况时间复杂度的一种特殊情况。
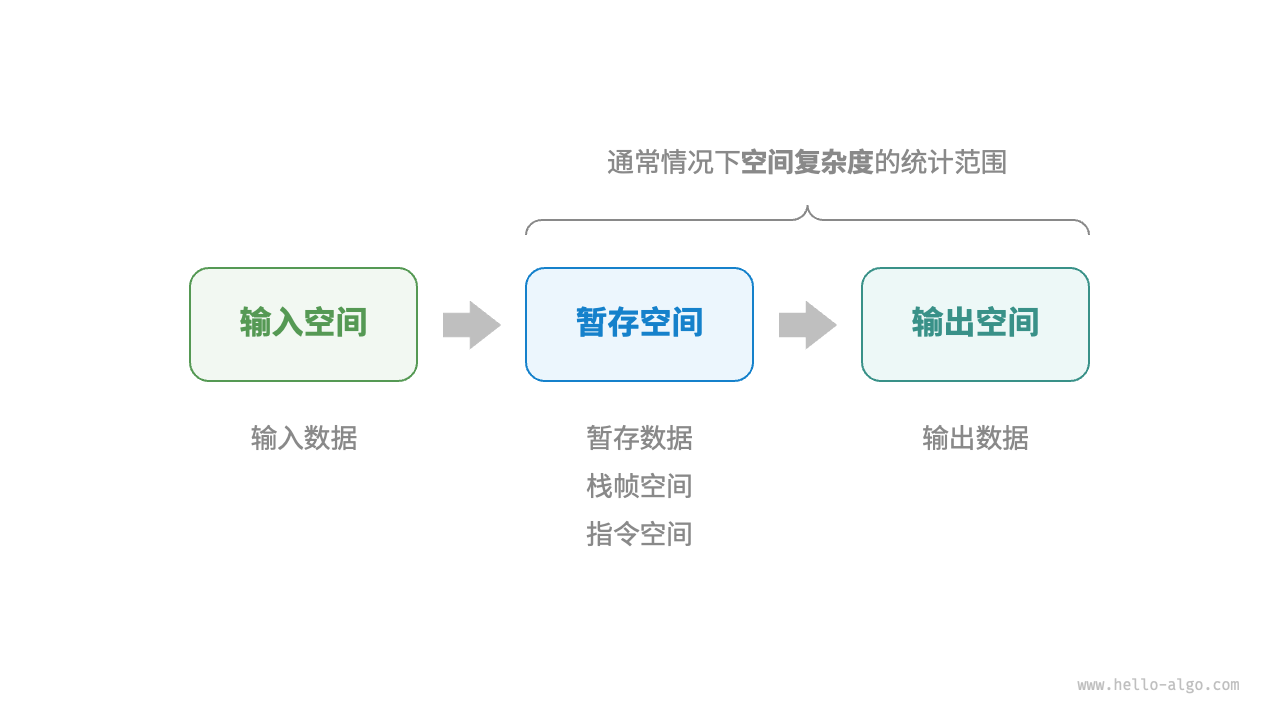
空间复杂度¶
算法运行过程中使用的内存空间主要包括
- 输入空间:存储算法的输入数据
- 暂存空间
- 暂存数据:保存算法运行过程中的各种常量、变量、对象等
- 栈桢空间:保存调用函数的上下文数据
- 指令空间:保存编译后的程序指令
- 输出空间:存储算法的输出数据
class Node:
"""类"""
def __init__(self, x: int):
self.val: int = x # 节点值
self.next: Node | None = None # 指向下一节点的引用
def function() -> int:
"""函数"""
# 执行某些操作...
return 0
def algorithm(n) -> int: # 输入数据
A = 0 # 暂存数据(常量,一般用大写字母表示)
b = 0 # 暂存数据(变量)
node = Node(0) # 暂存数据(对象)
c = function() # 栈帧空间(调用函数)
return A + b + c # 输出数据
空间复杂度通常只统计暂存数据、栈帧空间和输出数据三部分
常数阶¶
常数阶常见于数量与输入数据大小 \(n\) 无关的常量、变量、对象
在循环中初始化变量或调用函数而占用的内存,在进入下一循环后栈桢空间就会被释放,因此不会累积占用空间,,所以虽然循环了 \(n\) 次,时间复杂度为 \(O(n)\),但空间复杂度仍为 \(O(1)\)
def function() -> int:
return 0
def constant(n: int):
# 常量、变量、对象占用 O(1) 空间
a = 0
nums = [0] * 10000
node = ListNode(0)
# 循环中的变量占用 O(1) 空间
for _ in range(n):
c = 0
# 循环中的函数占用 O(1) 空间
for _ in range(n):
function()
线性阶¶
线性阶常见于元素数量与 \(n\) 成正比的数组、链表、栈、队列等
def linear(n: int):
# 长度为 n 的列表占用 O(n) 空间
nums = [0] * n
# 长度为 n 的哈希表占用 O(n) 空间
hmap = dict[int, str]()
for i in range(n):
hmap[i] = str(i)
def linear_recur(n: int):
print("递归 n =", n)
if n == 1:
return
# 时间和空间复杂度都为 O(n)
linear_recur(n - 1)
平方阶¶
平方阶常见于矩阵和图,元素数量与 \(n\) 成平方关系
def quadratic(n: int):
# 二维列表占用 O(n^2) 空间
num_matrix = [[0] * n for _ in range(n)]
指数阶¶
指数阶常见于二叉树
def build_tree(n: int) -> TreeNode | None:
"""指数阶(建立满二叉树)"""
if n == 0:
return None
root = TreeNode(0)
root.left = build_tree(n - 1)
root.right = build_tree(n - 1)
return root
对数阶¶
对数阶常见于分治算法,例如归并排序。